Database Transaction คืออะไรกันนะ?

Introduction
ในโลกของฐานข้อมูล การมี Data Integrity, Consistency และ Reliability นั้นเป็นเรื่องที่สำคัญอย่างยิ่ง ไม่ว่าจะเป็น Application ขนาดเล็กหรือใหญ่ โดยวิธีการที่จะทำให้มีสิ่งที่กล่าวมาข้างต้นนั้นจำเป็นจะต้องมีการใช้งาน Database Transaction ซึ่งเดี๋ยวเราจะมาเรียนรู้ไปด้วยกันครับว่าเจ้า Transaction เนี่ย มันคืออะไรและมีประโยชน์ยังไง
ปัญหาเมื่อไม่ได้ใช้งาน Transaction
ก่อนอื่น ก่อนจะไปดูความหมายของ Transaction เรามาดูกันก่อนว่า ถ้าไม่ได้ใช้งาน Transaction จะเกิดปัญหาอะไรขึ้น จริง ๆ มีอยู่หลายปัญหาเลย แต่ผมจะยกตัวอย่างปัญหาสุดคลาสสิกละกันครับ

มีผู้ใช้คนหนึ่งต้องการซื้อดินสอ 2 แท่ง (ปัจจุบันมีอยู่ 3 แท่ง) โดยมีการใช้ UPDATE operation ลดจำนวนดินสอกลายเป็น 1 แท่ง แต่การซื้อสินค้าก็ไม่น่าจะมีแค่การลดจำนวนสินค้าเฉย ๆ ถูกไหมครับ อาจจะต้องมี Operation อื่น ๆ เพิ่มเติมด้วย อย่างเช่น INSERT operation (เพิ่มข้อมูล Payments) แต่ INSERT operation นี้ดันทำงานผิดพลาด ส่งผลให้ผู้ใช้งานเห็นว่าการซื้อดินสอของตนไม่สำเร็จ ปัญหาที่เกิดขึ้นคือ จำนวนดินสอในฐานข้อมูลเหลือเพียงแค่ 1 แท่ง ทั้ง ๆ ที่ไม่ได้ถูกขายออกไปจริง ๆ
Transaction คืออะไร?
ผมให้คำนิยามแก่ Database Transaction สั้น ๆ คือ “A Collection of Operations” ละกันครับ สั้น ๆ ง่าย ๆ โดย Operations นี้จะหมายถึงพวก SELECT, INSERT, UPDATE และ DELETE โดยใน 1 Transaction เนี่ย สามารถมีได้หลาย Operations มาก ๆ ลองดูตัวอย่างจากรูปด้านล่างนี้ครับ
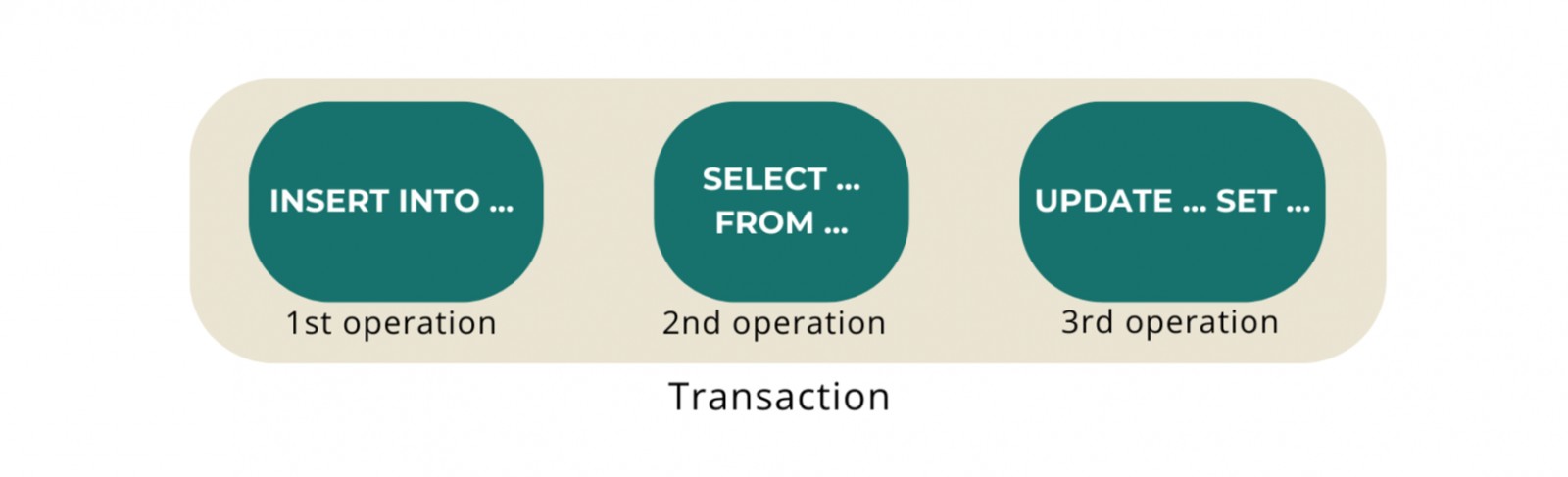
ใน Transaction นี้ ประกอบไปด้วย 3 Operations คือ INSERT, SELECT และ UPDATE โดย Operations เหล่านี้จะทำงานตามลำดับ นั่นก็คือ INSERT → SELECT → UPDATE
ซึ่งการประกาศใช้งานก็ง่าย ๆ เลยครับ สังเกตจากโค้ดด้านล่าง
BEGIN;
INSERT INTO ...;
SELECT ... FROM ...;
UPDATE ... SET ...;
COMMIT;
BEGIN คือ การประกาศเริ่มต้นใช้งาน Transaction
COMMIT คือ การประกาศสิ้นสุดการทำงานของ Transaction (ทำงานสำเร็จ)
อาจจะมีคำถามว่า อ้าว แล้วการมี Transaction มาครอบพวก Operations เหล่านี้ มันช่วยแก้ปัญหาการซื้อดินสอเมื่อกี้ยังไง ?
เดี๋ยวเรามาทำความเข้าใจไปด้วยกัน
คุณสมบัติของ Database Transaction — ACID
หลาย ๆ คนอาจเคยได้ยิน ACID กันมาบ้างแล้ว แต่วันนี้เราจะมาลงลึกกันครับว่าแต่ละตัวคืออะไร และมีความสำคัญยังไง
ACID หรือ Atomicity, Consistency, Isolation, Durability คือ คุณสมบัติของ Relational Database Transaction โดยแต่ละคุณสมบัติก็จะช่วยแก้ปัญหาในเรื่องที่แตกต่างกันออกไป รวมถึงปัญหาการซื้อดินสอเมื่อกี้ด้วย
A — Atomicity
Atomicity คือ คุณสมบัติที่รับรองว่า Operations ใน Transaction ต้องทำงานสำเร็จทั้งหมด หรือไม่ ก็ต้องไม่สำเร็จทั้งหมด อ่านแล้วอาจจะงง ๆ นะครับ ผมจะยกตัวอย่างง่าย ๆ ดีกว่า โดยเอาเป็นตัวอย่างการซื้อดินสอเมื่อกี้เลยละกันครับ
กรณีที่ 1: ทำงานสำเร็จทั้งหมด
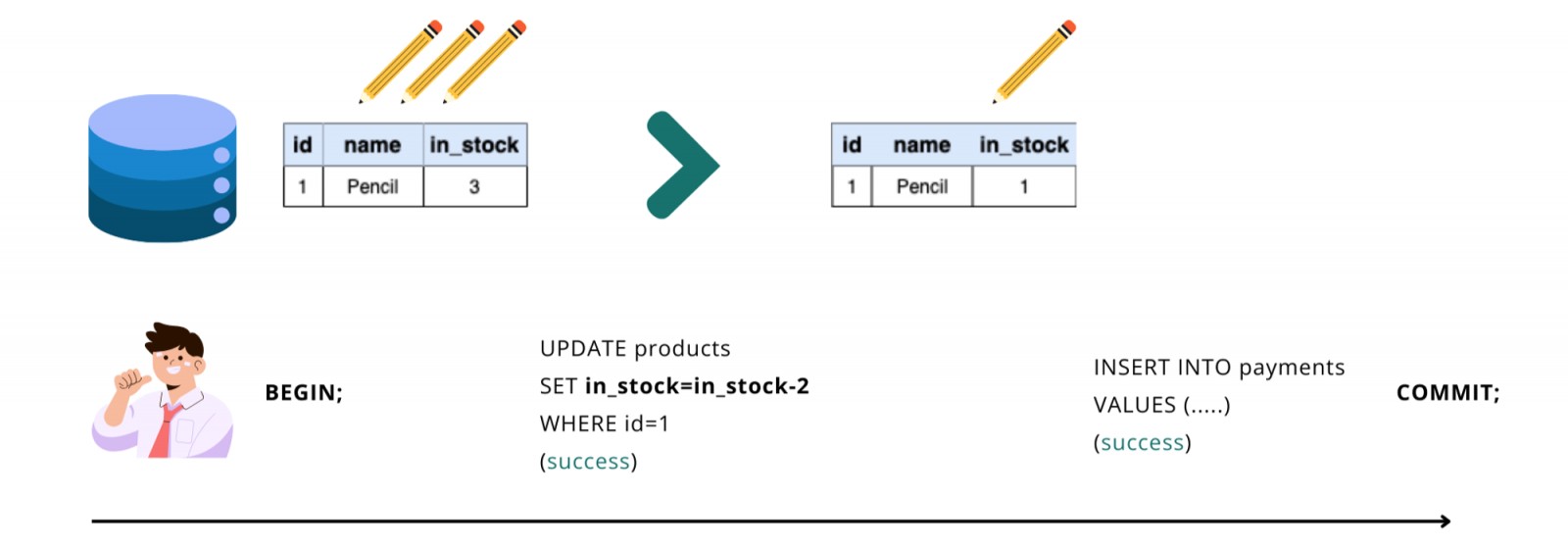
ทุก Operation ใน Transaction นี้ ทำงานสำเร็จทั้งหมด ทำให้ Transaction นี้ทำงานสำเร็จ (Committed)
กรณีที่ 2: มีบาง Operation ทำงานไม่สำเร็จ ทุก ๆ Operations ก็ต้องทำงานไม่สำเร็จด้วยกันทั้งหมด
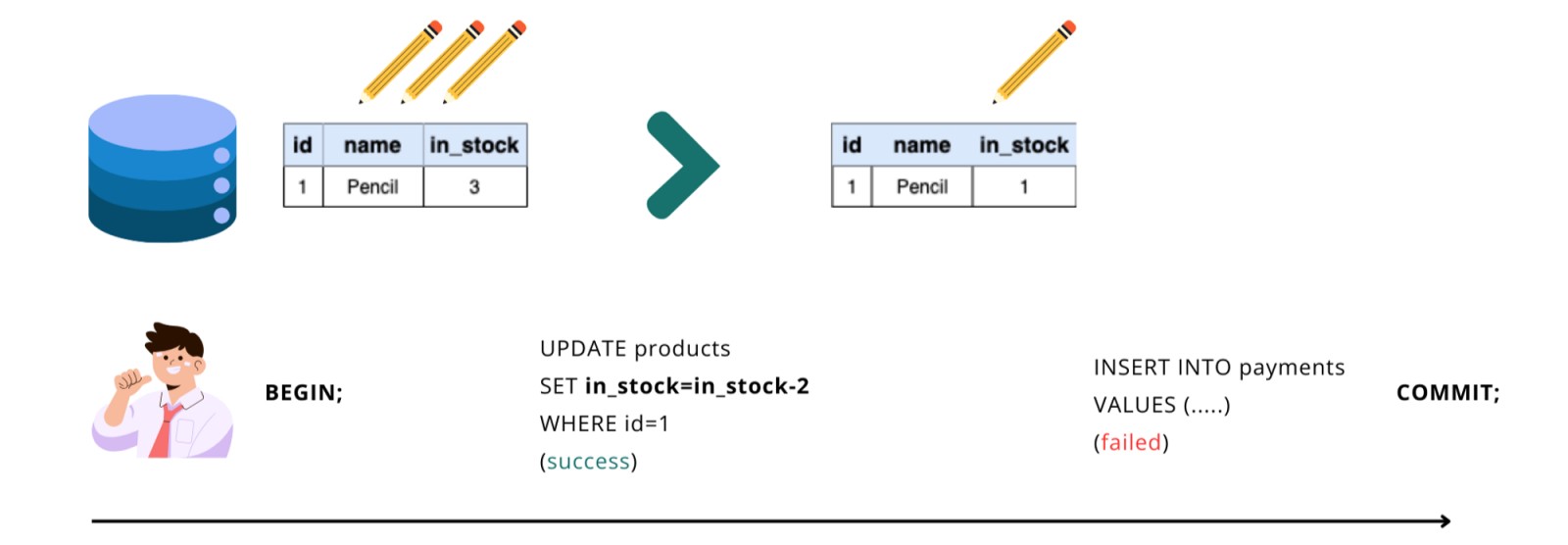
UPDATE operation ทำงานสำเร็จแล้ว (จำนวนดินสอกลายเป็น 1 แท่ง) แต่ต่อมา INSERT operation (สร้างข้อมูลการชำระเงิน) ทำงานผิดพลาด ส่งผลให้ Transacion นี้ถูก Rollback (Committed) การเปลี่ยนแปลงที่เกิดขึ้นจาก Operation ที่เคยทำงานสำเร็จ เช่น การ UPDATE จำนวนดินสอเป็น 1 แท่ง จะถูกย้อนกลับไปเป็น 3 แท่งเหมือนเดิม ราวกับว่า UPDATE operation นี้ไม่เคยเกิดขึ้นจริง (นี่แหละครับ เป็นการแก้ปัญหาการซื้อดินสอที่ผมเกริ่นไปก่อนหน้านี้)
C — Consistency
Consistency คือ คุณสมบัติที่รับรองว่าข้อมูลที่ถูกบันทึกในฐานข้อมูลจะต้องมีความ Consistent ทั้งก่อนและหลังเกิด Transaction ผลลัพธ์ที่เกิดขึ้นจาก Transaction จะต้องสามารถคาดเดาได้ โดยไม่มีความผิดปกติของข้อมูลเกิดขึ้น ซึ่งจะแบ่งได้ 2 กรณี ดังนี้
- ต้องไม่ละเมิด Constrains ที่กำหนดไว้ เช่น เราระบุ Column username ให้ Unique ต่อมาถ้ามีการ Insert ข้อมูลที่มี Username ซ้ำกับที่มีอยู่ก่อนแล้ว จะทำให้ INSERT operation นั้นไม่สำเร็จ และทำให้ Transaction ถูก Rollback
- ข้อมูลต้องมีความสอดคล้องกันทั้งก่อนและหลังเกิด Transaction เช่น บัญชี A และ B มีเงิน 1,000 บาทเท่ากัน ต่อมามีการโอนจากบัญชี A ไปยัง B 300 บาท ผลลัพธ์ที่เกิดขึ้น คือ บัญชี A ต้องเหลือเงิน 700 บาท และบัญชี B ต้องมีเงิน 1,300 บาท
I — Isolation
คุณสมบัตินี้สำคัญมาก ๆ ครับ เป็นคุณสมบัติที่รับรองว่าเมื่อมี Transaction > 1 กระทำกับข้อมูลชุดเดียวกัน ในเวลาเดียวกัน แต่ละ Transaction จะต้องไม่รบกวนกันและเป็นอิสระต่อกัน
โดย Isolation นี้มีอยู่หลาย Level ด้วยกัน แต่ละ Level มีการแก้ปัญหาที่เกิดขึ้นแตกต่างกัน เดี๋ยวเรามาดูกันครับว่ามีปัญหาอะไรเกิดขึ้นบ้าง และแต่ละ Isolation Levels แก้ปัญหาเหล่านั้นยังไงบ้าง
ปัญหาที่เกิดขึ้นเมื่อมี Transaction > 1 กระทำกับข้อมูลชุดเดียวกัน ในเวลาเดียวกัน มีดังนี้
- Dirty Read ยกตัวอย่างเช่น เมื่อ Transaction A มีการอ่านข้อมูลที่ถูกเปลี่ยนแปลงจาก Transaction B (ยังไม่ถูก Committed) แต่ Transaction B นั้นมีบางอย่างผิดพลาดเกิดขึ้น จึงเกิดการ Rollback เราเรียกการอ่านของ Transaction A ว่าเป็น “Dirty Read” (อ่านการเปลี่ยนแปลงที่ภายหลังถูก Rollback)
- Non-repeatable Read เกิดขึ้นเมื่อมี Transaction ที่มี SELECT Operation Query record เดิมมากกว่า 1 ครั้ง แต่การ Query ได้ค่าไม่เหมือนกัน (อ่านแล้วอาจจะงง ๆ รอดูตัวอย่างถัดไปดีกว่าครับ)
- Phantom Reads คล้ายกับ Non-repeatable Read แต่แตกต่างกันแค่ Phantom Read จะเกิดกับ Query ที่มีความเกี่ยวข้องกับ Record ตั้งแต่ 2 Records ขึ้นไป (อาจจะงงเหมือนเดิม รอดูตัวอย่างหลังจากนี้กันครับ)
Level ของ Isolation มีด้วยกัน 4 Levels
- Read Uncommitted
- Read Committed
- Repeatable Read
- Serializable
แต่ละ Levels แก้ปัญหาอะไรบ้าง ดูจากตารางนี้ได้เลยครับ
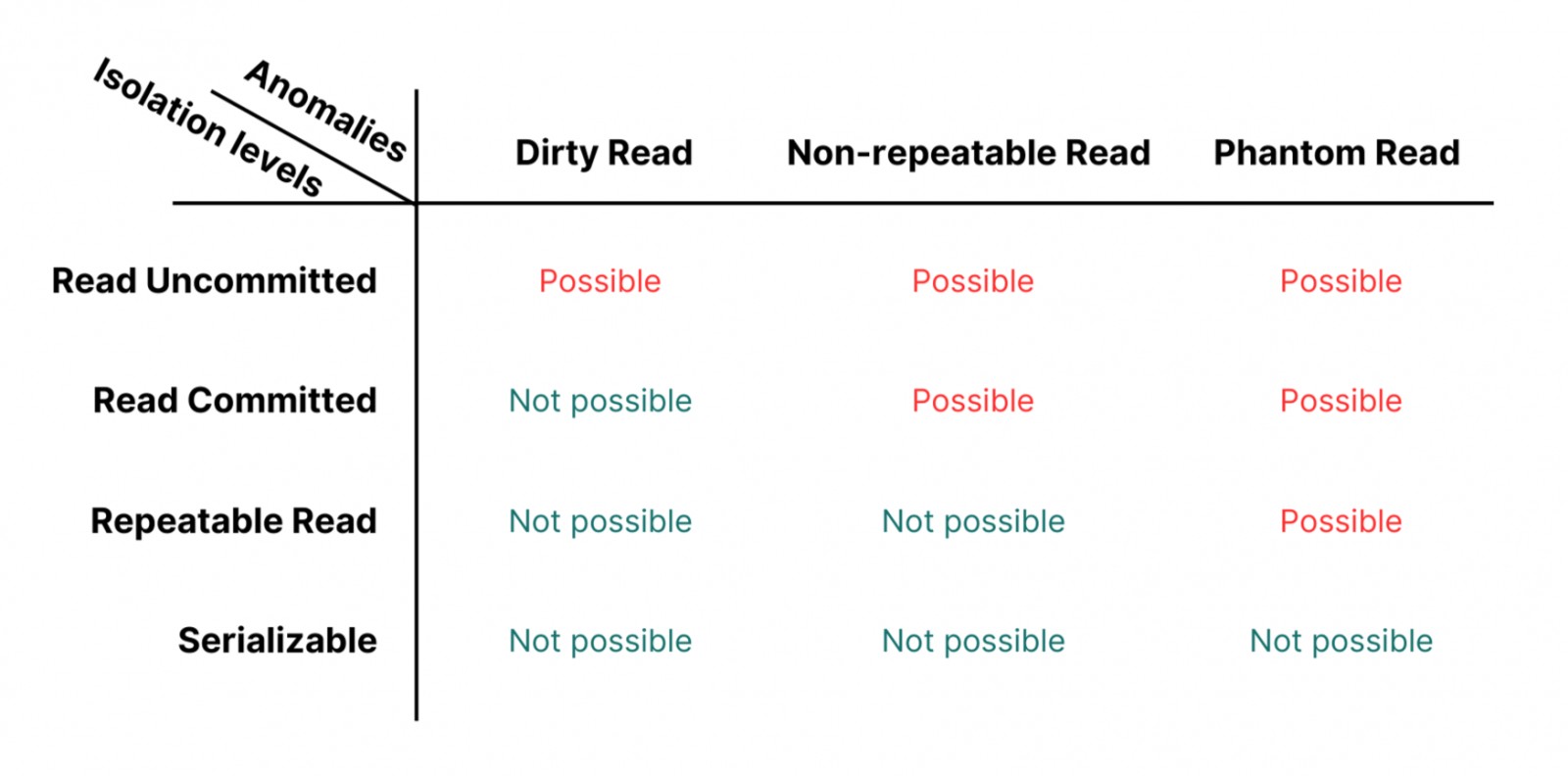
จากนี้เรามาดูกันครับว่าแต่ละ Level มีการทำงานยังไง และจัดการแต่ละปัญหาได้อย่างไร
1. Read Uncommitted
SET GLOBAL TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
Read Uncommitted เป็น Level ที่ต่ำที่สุด ถ้าเรา Set เป็น Level นี้ จะมีโอกาสเกิดปัญหาทั้ง 3 อย่างเลย
ยกตัวอย่างการเกิดปัญหา Dirty Read
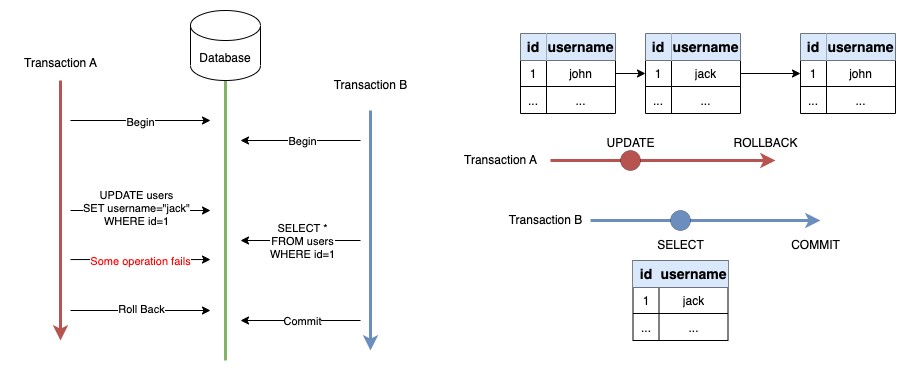
Transaction A มีการเปลี่ยน Username จาก “john” เป็น “jack” จากนั้น Transaction B อ่านค่าได้เป็น “jack” แต่ Operation ถัดมา ของ Transaction A ดันเกิดข้อผิดพลาด ส่งผลให้ Transaction A ถูก Rollback จึงทำให้ค่าที่ Transaction B อ่านเป็น Dirty Read (อ่านค่าที่ถูก Rollback)
2. Read Committed
SET GLOBAL TRANSACTION ISOLATION LEVEL READ COMMITTED;
Read Committed เป็น Level ที่สูงขึ้นมาอีกหน่อย โดยหลักการทำงานคือ การอ่าน (SELECT) จะได้รับข้อมูลที่ถูก commit แล้วเท่านั้น จึงช่วยแก้ปัญหา Dirty Read ได้
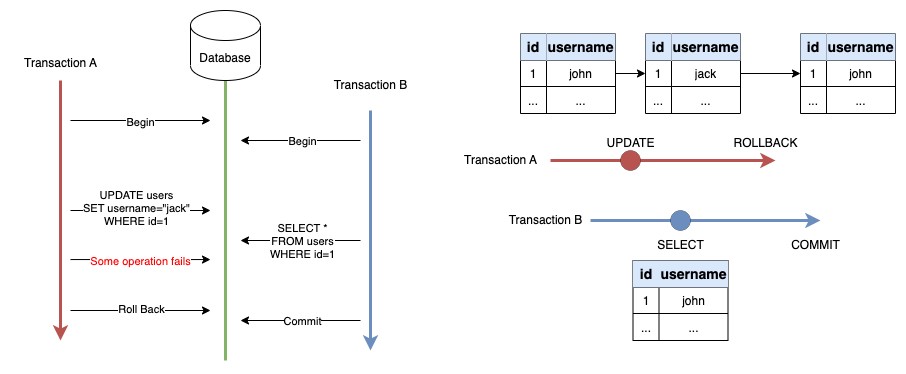
จากตัวอย่าง ค่าที่ Transaction B อ่านได้จะเป็น “john” เพราะ Transaction A (เปลี่ยน Username เป็น “jack”) ยังไม่ถูก Commit
แต่ แต่ แต่ .. Level นี้ก็ยังมีโอกาสเกิดอีก 2 ปัญหา นั่นก็คือ Non-repeatable Read และ Phantom Reads
ยกตัวอย่างการเกิดปัญหา Non-repeatable Read
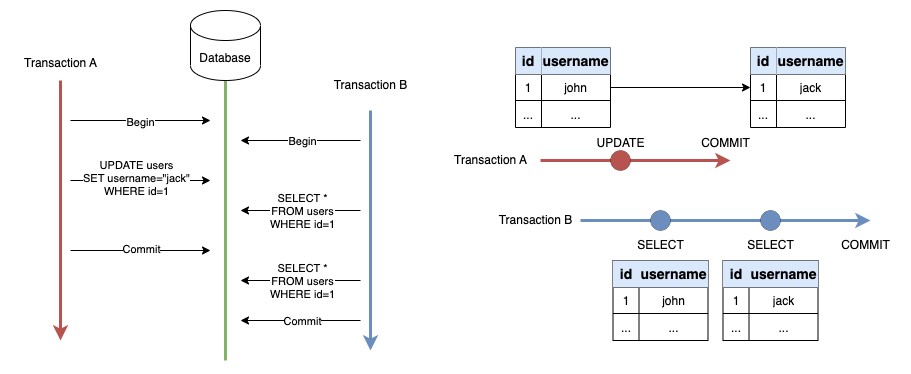
จากตัวอย่าง Read operation แรกใน Transaction B อ่านค่าได้เป็น “john” ซึ่งถูกต้องแล้ว เพราะจะอ่านได้ค่าที่ถูก Committed แล้วเสมอ แต่ Read operation ที่ 2 ดันอ่านค่าได้เป็น “jack” ซึ่งการอ่านค่าเดียวกันมากกว่า 1 ครั้งแล้วได้ค่าไม่ตรงกันนี่แหละครับ เราเรียกว่าเป็นปัญหา Non-repeatable Read
3. Repeatable Read
SET GLOBAL TRANSACTION ISOLATION LEVEL REPEATABLE READ;
Level นี้ชื่อตรงตัวเลยครับ ชื่อแบบนี้ช่วยแก้ปัญหา Non-repeatable Read แน่นอน
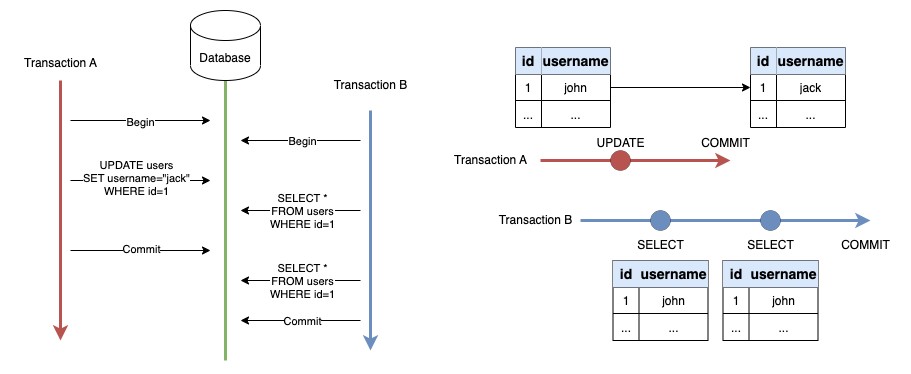
จากตัวอย่าง ทั้ง 2 Read operations ได้ค่าที่เหมือนกันทั้งคู่ แม้การเปลี่ยนแปลงจาก Transaction A จะถูก Commit ไปแล้วก็ตาม
แต่ แต่ แต่ .. Level นี้ก็มีโอกาสเจอปัญหาสุดท้ายของเราอยู่ครับ นั่นก็คือ Phantom Reads
โดย Phantom Reads อย่างที่ได้บอกไป มันมีความคล้ายกับ Non-repeatable Read ครับ เพียงแต่ Phantom Reads จะเป็นการอ่านที่มี Record ที่เกี่ยวข้องมากกว่า 1
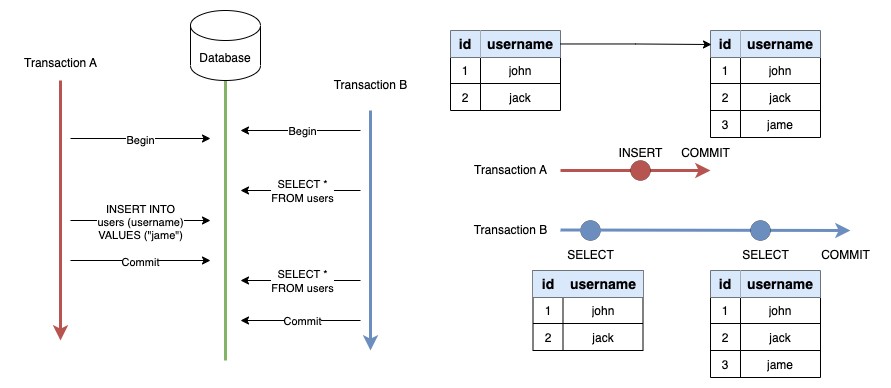
จากตัวอย่าง เรามีการอ่านข้อมูลทั้งหมดใน Table Users 2 ครั้งใน 1 Transaction แต่ข้อมูลที่ได้นั้นไม่ตรงกัน นี่แหละครับ Phantom Reads
ขอยกตัวอย่าง Phantom Reads อีกอันละกันครับ
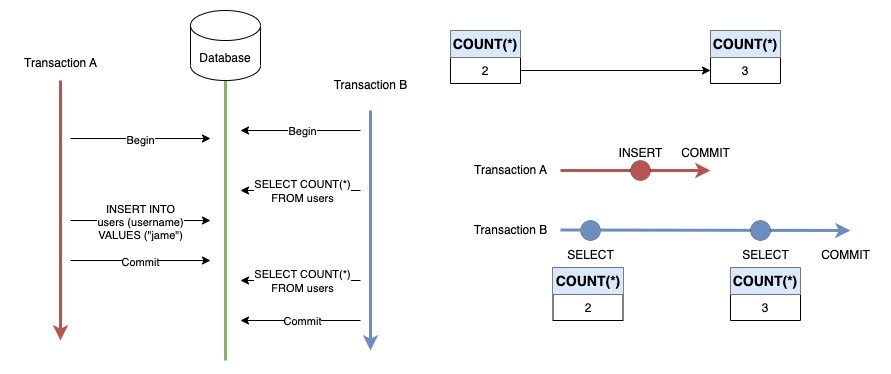
ไม่จำเป็นที่จะต้อง Query มาหลาย ๆ Records ก็ได้ครับ แค่ Read operation มีความเกี่ยวข้องกับหลาย ๆ Records แค่นี้ก็นับเป็น Phantom Reads แล้ว
4. Serializable
SET GLOBAL TRANSACTION ISOLATION LEVEL SERIALIZABLE;
Level นี้เป็น Level ที่สูงที่สุด ช่วยแก้ปัญหาได้ทั้ง 3 อย่างเลยครับ ถ้ามีมากกว่า 1 Transaction กระทำต่อข้อมูลชุดเดียวกันในเวลาเดียวกัน ในขณะเวลาหนึ่งจะมีเพียงแค่ 1 Transaction เท่านั้นที่กระทำกับข้อมูลชุดนั้น (Transaction อื่นรอไปก่อน) เป็นการทำงานแบบเรียงตามลำดับ
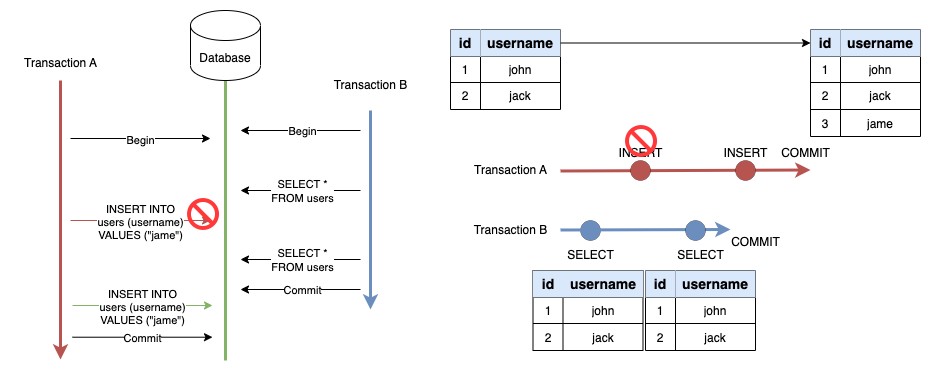
จากตัวอย่างเป็นการแก้ปัญหา Phantom Reads โดย Level นี้จะมีการ Block INSERT Operation ใน Transaction A ไว้ก่อน รอจนกว่า Transaction B จะทำงานจนเสร็จแล้วค่อยให้ INSERT operation ทำงานต่อ จึงสามารถแก้ทุก ๆ ปัญหาที่กล่าวมาได้ทั้งหมด
Serializable อาจจะดูเจ๋งนะครับที่แก้ทุกปัญหาได้หมดเลย แต่ก็มีสิ่งที่ควรตระหนักอยู่ นั่นก็คือ Level นี้อาจทำให้ Performance ของฐานข้อมูลดรอปลงได้ เมื่อมี Transaction จำนวนมาก ๆ กระทำต่อข้อมูลชุดเดียวกัน เพราะแต่ละ Transaction ก็จะรอ Transaction ก่อนหน้าทำงานจนเสร็จก่อน
คำแนะนำ: ควรเลือกใช้ Isolation level ที่เหมาะสมกับตัวระบบ เช่น ระบบที่ต้องการ Performance ที่ดีมาก ๆ โดยที่ไม่ Strict ในเรื่องข้อมูลซักเท่าไหร่ ก็เลือกเป็น Level ต่ำ ๆ อย่างเช่น Read Uncommitted หรือ Read Committed หรือระบบที่ Strict ในข้อมูลมาก ๆ อย่างเช่น ระบบเกี่ยวกับการเงิน หรือระบบซื้อขายสินค้า เลือกเป็น Serializable ก็ได้ครับ
D — Durability
Durability เป็นคุณสมบัติที่รับรองว่าเมื่อ Transaction ถูก Commit แล้ว การเปลี่ยนแปลงจะต้องถูกเก็บอย่างถาวร ไม่สูญหาย แม้ว่าฐานข้อมูลจะ Crash ก็ตาม
ขอเกริ่นไว้ก่อนนิดนึงครับ โดยปกติแล้วเมื่อมีการเขียนข้อมูล (INSERT, UPDATE, DELETE) การเปลี่ยนแปลงจะยังไม่ถูกเขียนลง Disk แต่จะถูกเขียนลง Buffer Cache ก่อน (เมื่อฐานข้อมูล Crash = ข้อมูลหาย) สาเหตุเป็นเพราะการเขียนลง Disk มันช้า แต่เขียนลง Cache มันเร็ว จำเรื่องนี้ไว้ให้ดีนะครับ เพราะมันสำคัญต่อส่วนถัดไปมาก ๆ
เมื่อฐานข้อมูลเกิดการ Crash และถูก Recovery ขึ้นมาใหม่ โดยทั่วไปแล้ว RDBMS จะใช้เทคนิค 2 เทคนิคร่วมกันสำหรับการกู้คืนข้อมูลที่สูญหาย คือ Checkpointing และ Write-ahead Logging
Recovery Technique — Checkpointing
DBMS จะมีการสร้าง Checkpoint ขึ้นมาตามเวลาที่กำหนด สมมุติกำหนดไว้ที่ 1 ชั่วโมง หมายความว่า Checkpoint จะถูกสร้างใหม่ขึ้นมาทุก ๆ 1 ชั่วโมง เมื่อฐานข้อมูลถูก Recover ขึ้นมา มันจะโฟกัสการเปลี่ยนแปลงจาก Transactions ที่เกิดขึ้นหลังจาก Checkpoint ล่าสุดเป็นหลัก
ตัวอย่าง
สมมุติว่าเรากำหนดเวลาสร้าง Checkpoint ไว้ที่ 1 ชั่วโมง
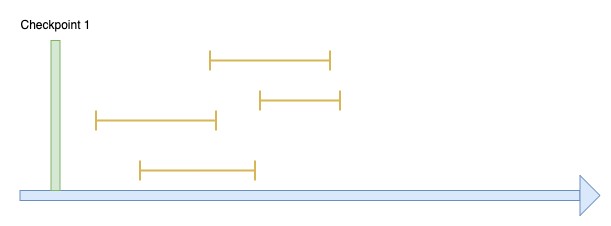
จากรูป มีการสร้าง Checkpoint แรกขึ้นมา และมีหลาย Transactions เกิดขึ้น (เส้นสีเหลือง 1 เส้น = 1 Transaction) โดยการเปลี่ยนแปลงที่เกิดจาก Transaction เหล่านี้จะยังถูกเก็บใน Buffer Cache ซึ่งมีโอกาสสูญหายได้ถ้าฐานข้อมูล Crash
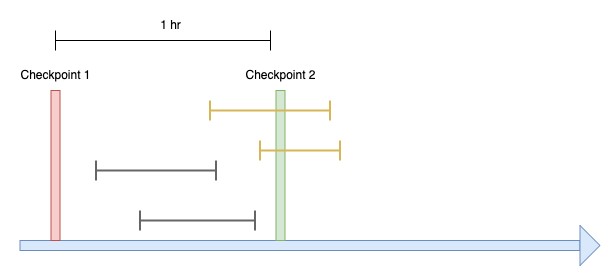
ผ่านไป 1 ชั่วโมง มีการสร้าง Checkpoint อันที่ 2 ขึ้นมา ทำให้การเปลี่ยนแปลงจาก Transactions ที่อยู่ระหว่าง Checkpoint 1 และ Checkpoint 2 จะถูกย้ายจาก Buffer Cache ไปเก็บยัง Disk เราเรียกการย้ายนี้ว่า การ Flush ซึ่งหมายความว่าข้อมูลที่ถูก Flush แล้วจะไม่สูญหาย
นี่แหละครับคือสาเหตุว่าทำไมฐานข้อมูลจึงโฟกัสไปที่การเปลี่ยนแปลงจาก Transaction ที่เกิดขึ้นหลังจาก Checkpoint ล่าสุดเสมอ
หมายเหตุ:
เส้นสีดำ = การเปลี่ยนแปลงจาก Transaction ที่ถูก Flush แล้ว
เส้นสีเหลือง = การเปลี่ยนแปลงจาก Transaction ที่ยังอยู่ใน Buffer Cache
แล้วเมื่อฐานข้อมูลถูก Recover ขึ้นมาแล้ว มันรู้ได้ยังไงว่าข้อมูลที่สูญหายไปมีหน้าตายังไง?
คำตอบอยู่ในเทคนิคถัดไปครับ
Recovery Technique — Write-ahead logging (WAL)
เมื่อ Write operations (INSERT, UPDATE, DELETE) ใน Transaction ทำงาน จะมีการเก็บรายละเอียดของ Operations เหล่านั้นในรูปแบบของ Log (1 log / 1 operation) โดยจะเก็บ Log เหล่านี้ลงใน Disk แบบ Append-only ทำให้มีความเร็วในการเขียนที่สูง ซึ่งข้อมูลใน Log ก็จะประกอบไปด้วย Transaction ID, ค่าเก่า, ค่าใหม่, Operation type (จริง ๆ เก็บเยอะกว่านี้ครับ แต่ยกตัวอย่างมาบางส่วนเพื่อความเข้าใจ)
ตัวอย่าง
BEGIN;
UPDATE users SET username="jack" WHERE id=1;
INSERT INTO users (username) VALUES ("jame");
COMMIT;
จะได้ logs มาประมาณนี้
{
"transaction_id": "abc-123",
"old_value": "john",
"new_value": "jack",
"operation_type": "update"
}
{
"transaction_id": "abc-123",
"old_value": "",
"new_value": "jame",
"operation_type": "insert"
}
logs เหล่านี้แหละครับที่ฐานข้อมูลจะนำมาใช้ในการกู้คืนข้อมูลที่สูญหาย
Checkpointing + Write-ahead Logging
เมื่อนำทั้ง 2 เทคนิคมาใช้ร่วมกัน ก็จะได้การทำงานประมาณนี้ครับ
ทุก ๆ Operations ใน Transaction จะถูกบันทึกรายละเอียดในรูปแบบของ Log (Write-ahead logging) โดยเราจะโฟกัสไปที่ Logs จาก Operations ที่อยู่ใน Transactions ที่เกิดขึ้นถัดจาก Checkpoint อันล่าสุด (Checkpointing) เมื่อฐานข้อมูลถูก Recover ขึ้นมาใหม่ มันก็จะนำ Transactions ที่อยู่ถัดจาก Checkpoint อันล่าสุด มาทำงานใหม่อีกครั้ง โดยยึดรายละเอียดการทำงานของแต่ละ Transaction ตาม Log ที่บันทึกไว้
ด้วยเทคนิคเหล่านี้แหละครับ ที่ช่วยให้ข้อมูลไม่สูญหายแม้ว่าฐานข้อมูลจะ Crash ก็ตาม
Final Word
บล็อคนี้เป็นบล็อคแรกที่ผมเขียนเลยครับ หวังว่าจะเป็นประโยชน์ต่อผู้ใช้งานฐานข้อมูลทุกคน ถ้าผิดพลาดในจุดไหนต้องขออภัยมา ณ ที่นี้ด้วยครับ ขอบคุณทุกคนที่อ่านกันจนจบนะครับ
tags : database relational database mysql thinknet software engineer