Read Concern กับ Write Concern ใน MongoDB คืออะไรกันนะ?

Introduction
การจัดการเรื่องความ Consistency ของข้อมูลในโลกของ MongoDB เป็นเรื่องที่สำคัญอย่างยิ่ง จึงเป็นที่มาของเนื้อหาในบล็อคนี้ครับ
MongoDB ได้มอบ Configurations ที่สำคัญอย่าง Read Concern และ Write Concern มาเพื่อให้เราสามารถควบคุมพฤติกรรมของการ Read และ Write ได้ มาทำความรู้จักกับ 2 Configurations นี้ไปพร้อม ๆ กันดีกว่าครับ
ในบล็อกนี้ผมจะโฟกัสไปที่ Cluster แบบ Replica Set Cluster นะครับ แต่จริง ๆ แล้ว Read Concern หรือ Write Concern นั้นสามารถใช้ได้กับ Sharded Cluster หรือ Single Instance ด้วย เพียงแต่อาจมีข้อจำกัดบางอย่างที่แตกต่างกันเล็กน้อย
Read Concern คืออะไร?
Read Concern คือ Configuration ที่ช่วยให้เราควบคุมความ Consistency ของการ Read ข้อมูลจาก MongoDB ได้ โดยเราสามารถเลือก Read Concern ได้ถึง 5 ระดับเลยครับ โดยแต่ละระดับนั้นมีข้อดีข้อเสียที่แตกต่างกันออกไป ขึ้นอยู่กับว่าระบบของเรานั้นต้องการใช้ระดับไหน แต่ในบล็อกนี้ผมจะพูดถึงเฉพาะ 3 ระดับที่มีโอกาสได้ใช้บ่อยละกันครับ
Local (default)
การกำหนด Read Concern เป็น local (readConcern: ‘local’) จะทำให้การอ่านข้อมูลจาก MongoDB นั้นได้รับข้อมูลล่าสุดที่อยู่ใน Node ที่อ่านทันที โดยไม่คำนึงว่าข้อมูลที่ได้รับถูก Acknowledge จาก Nodes ส่วนใหญ่ใน Cluster แล้วหรือยัง หมายความว่าข้อมูลที่ได้รับมีโอกาสถูก Rollback ได้ในภายหลัง ซึ่งสาเหตุที่ข้อมูลถูก Rollback ก็อย่างเช่น Write Operation มีการทำงานผิดพลาด หรือไม่ก็ Primary Node ดัน Crash ก่อนที่ข้อมูลจะถูก Replicate ไปยัง Nodes อื่น ๆ
อธิบายเพิ่มเติมครับ Acknowledgement หมายถึงการที่ Node มีการตอบกลับมาว่า ข้อมูลจะถูกบันทึกไว้ที่ Node นั้นอย่างแน่นอน เมื่อข้อมูลที่ว่านั้นถูก Acknowledge จาก Nodes ส่วนใหญ่ใน Cluster แล้วก็จะไม่มีโอกาสถูก Rollback ได้อีก Acknowledgement นั้นจะเกิดขึ้นเฉพาะกับ Write Operation นะครับ จะไม่เกิดกับ Read operation
คำว่า “Acknowledge” หลังจากนี้ข้อใช้เป็นคำว่า “Ack” นะครับ
จากที่ได้บอกไปก่อนหน้าครับว่า ถ้ากำหนด Read Concern เป็น Local ข้อมูลที่เราได้รับจะไม่ถูกสนใจว่าถูก Ack จาก Nodes ส่วนใหญ่แล้วหรือยัง ขอแค่เป็นข้อมูลล่าสุดที่อยู่ใน Node ที่อ่านก็พอ มาดูตัวอย่างเพื่อความเข้าใจกันครับ
ตัวอย่าง
สมมุติให้
- ข้อมูลที่ถูกเก็บอยู่คือ {name: ‘john’}
- Write1 คือ Operation ที่ Update ข้อมูลจาก {name: ‘john’} เป็น {name: ‘jack’}
- กำหนดให้ Write Concern เป็น w: 1
ยังไม่ต้องทำความเข้าใจ Write Concern ก็ได้ครับ เอาเป็นว่า w: 1 หมายความว่า Write Operation เช่น การ Insert, Update, Delete จะทำงานสำเร็จก็ต่อเมื่อข้อมูลถูกเขียนลง Primary Node แล้ว (เขียนลง Primary Node ปุ๊บก็จะถือว่า Write Operation นั้นสำเร็จ โดยไม่ต้องรอให้ข้อมูล Replicate ไปยัง Nodes อื่น ๆ)
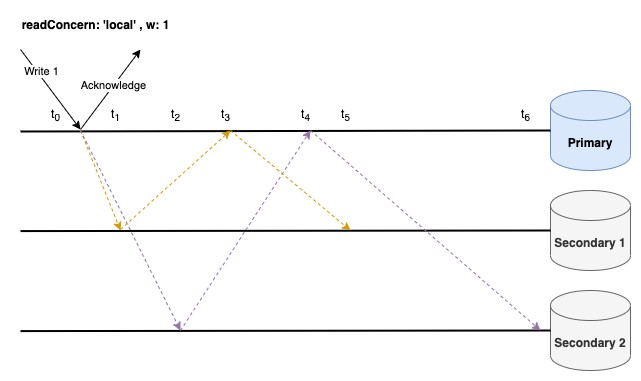
ลำดับเหตุการณ์
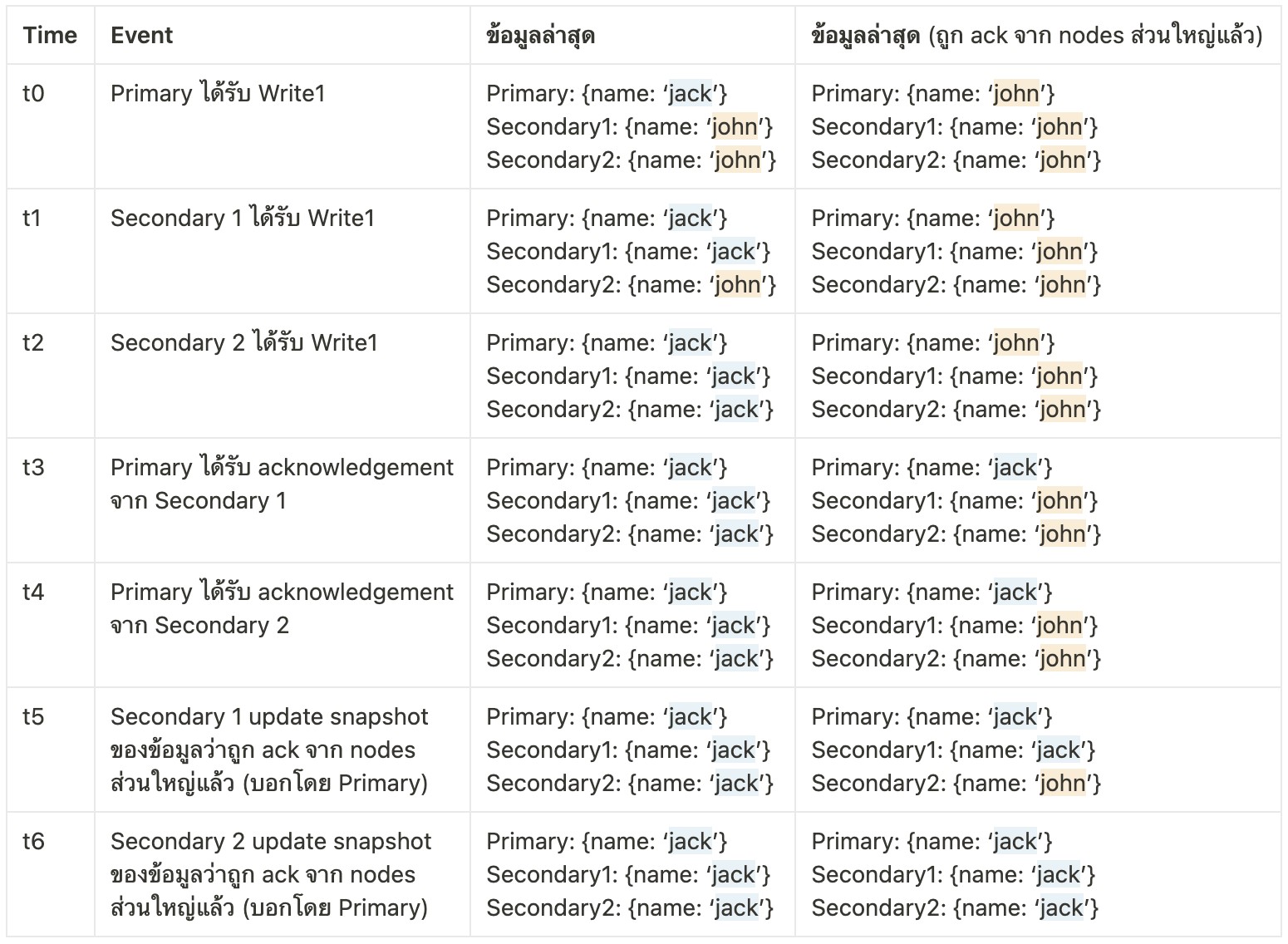
ข้อมูลที่อ่านได้ในช่วงเวลาต่าง ๆ
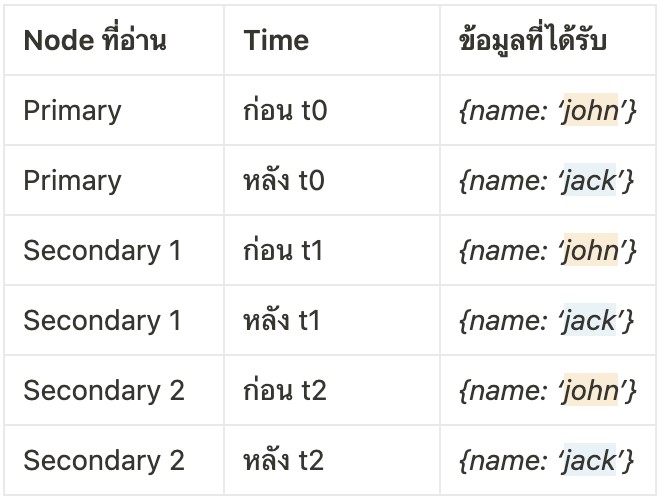
เมื่อมีการอ่านข้อมูลจาก Primary ณ เวลา t0 ก็จะได้รับ {name: ‘jack’} ทันที เช่นเดียวกันกับการอ่านข้อมูลจาก Secondary 1 ณ เวลา t1 และการอ่านข้อมูลจาก Secondary 2 ณ เวลา t2
ตั้งคำถามเล่น ๆ ถ้าเกิดว่าเราอ่านข้อมูลนี้จาก Secondary 1 ณ เวลา t5 ล่ะ ข้อมูลที่ได้มีโอกาสถูก rollback อยู่ไหม?
คำตอบคือ ไม่ครับ เนื่องจาก ณ เวลา t5 ข้อมูล {name: ‘jack’} ถูก ack จาก Nodes ส่วนใหญ่แล้ว (ถูกแจ้งโดย Primary นั่นเอง เพราะ Primary ได้รับ Acknowledgement จาก Secondary 1 และตัวมันเองแล้ว จึงแจ้ง Secondary 1 ว่าข้อมูลนี้ได้ถูก Ack จาก Nodes ส่วนใหญ่แล้ว)
ข้อดี - ได้รับข้อมูลที่เป็นข้อมูลล่าสุดเสมอ
ข้อเสีย - มีโอกาสได้รับข้อมูลที่มีโอกาสถูก rollback
Majority
การกำหนด Read Concern เป็น Majority (readConcern: ‘majority’) จะทำให้มั่นใจได้ว่าข้อมูลที่ได้จากการอ่านนั้นได้รับ Acknowledgement จาก Nodes ส่วนใหญ่แล้วหมายความว่า ข้อมูลที่อ่านจะไม่มีโอกาสถูก Rollback ได้อีก
ถ้าใน Cluster ประกอบไปด้วย 1 Primary, 2 Secondaries → จำนวน Nodes ส่วนใหญ่ก็คือ 2
ตัวอย่าง
สมมุติให้
- ข้อมูลที่ถูกเก็บอยู่คือ {name: ‘john’}
- Write1 คือ Operation ที่ Update ข้อมูลจาก {name: ‘john’} เป็น {name: ‘jack’}
- กำหนดให้ Write Concern เป็น w: 1
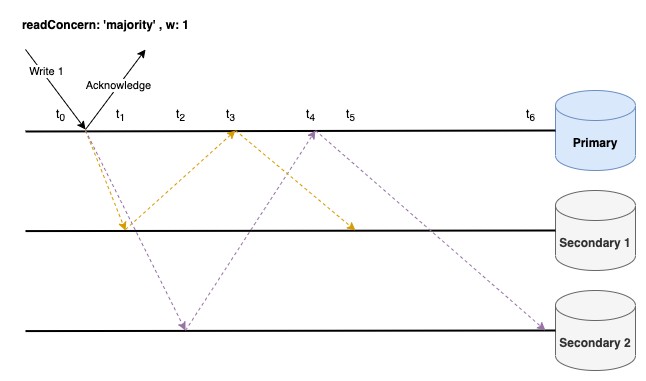
ตารางแสดงลำดับเหตุการณ์
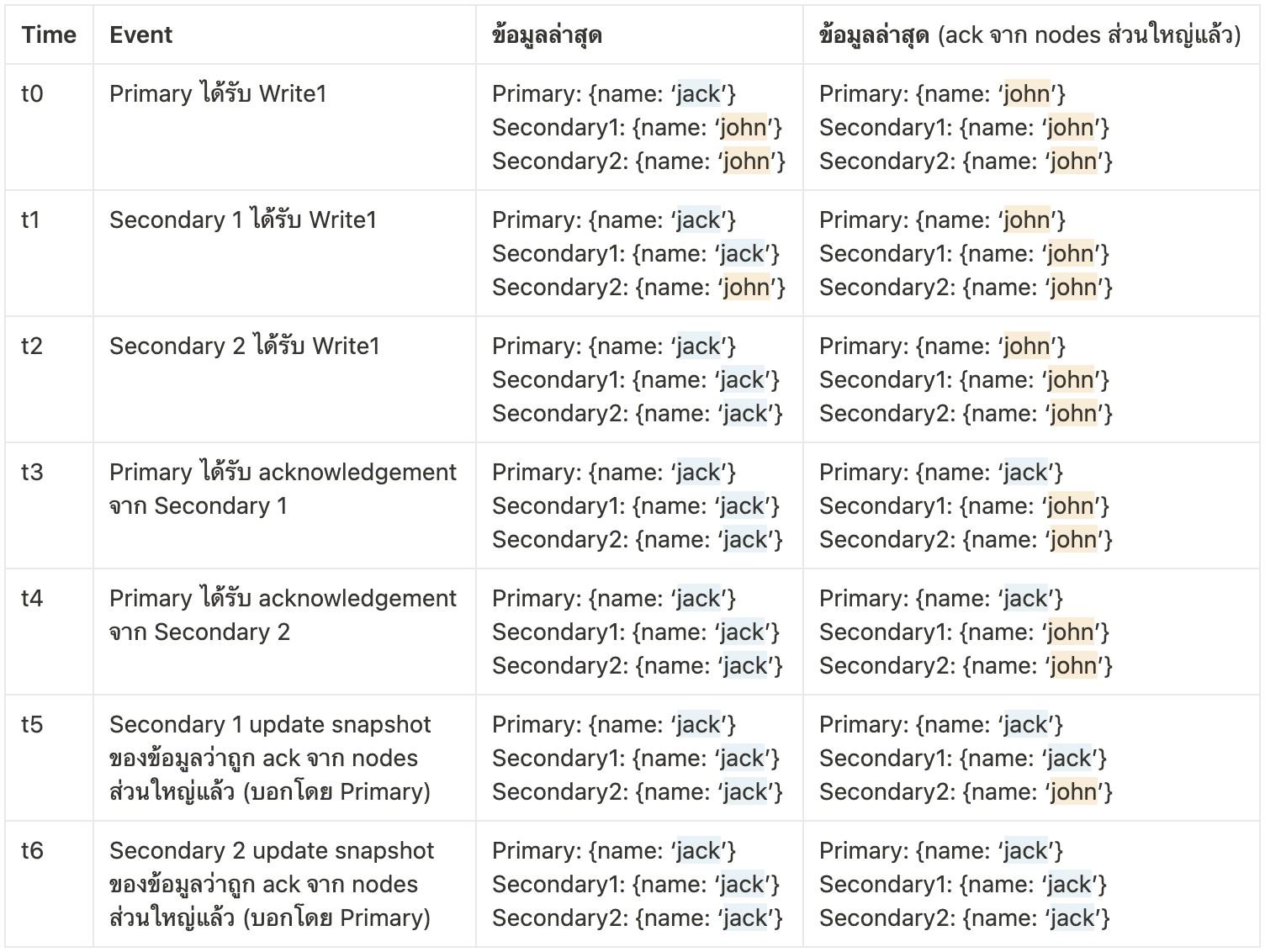
ข้อมูลที่อ่านได้ในช่วงเวลาต่าง ๆ

จากตัวอย่าง การอ่านที่ Secondary 1 ก่อนเวลา t5 จะได้ค่ามาเป็น {name: ‘john’} (เพราะ {name: ‘john’} เคยถูก Ack จาก Node ส่วนใหญ่มาก่อนแล้ว) แม้ว่า Secondary 1 จะ Ack ณ เวลา t1 แล้วก็ตาม แต่ {name: ‘jack’} ก็ยังไม่ถือว่าถูก Ack จาก Node ส่วนใหญ่ ต้องรอให้ Primary มีการแจ้งมาบอกว่า {name: ‘jack’} ได้รับการ Ack จาก Node ส่วนใหญ่แล้วนะ (Primary และ Secondary 1)
ข้อดี - ข้อมูลที่ได้รับ ไม่มีโอกาสถูก Rollback
ข้อเสีย - ข้อมูลที่ได้รับอาจจะไม่ใช่ข้อมูลล่าสุด
Snapshot
การกำหนด Read Concern เป็น Snapshot นั้นมีความเหมือนกับการกำหนด Read Concern เป็น Majority เลยครับ คือจะ Read ข้อมูลที่ถูก Ack จาก Node ส่วนใหญ่แล้วเท่านั้น เพียงแต่การอ่านข้อมูลชุดเดียวกันมากกว่า 1 ครั้งใน Transaction เดียวกัน จะได้ข้อมูลเดียวกัน ทำให้ไม่เกิดปัญหา Non-repeatable Read และ Phantom Read
Non-repeatable Read คือ ปัญหาการอ่าน Document เดียวกันมากกว่า 1 ครั้งใน Transaction เดียวกัน ได้ค่าไม่ตรงกัน ตัวอย่างเช่น ใน Transaction เดียวกันมีการอ่าน Document เดียวกัน 2 ครั้ง การอ่านครั้งแรกได้ {name: ‘john’} แต่การอ่านครั้งที่ 2 ดันได้ {name: ‘jack’} ซึ่งสาเหตุการอ่านค่าไม่ตรงกันนี้อาจจะเกิดจากมี Transaction อื่นเปลี่ยน Name เป็น ‘jack’ ก่อนการอ่านครั้งที่ 2
Phantom Read คือ ปัญหาคล้ายกับ Non-repeatable Read เลย คือการอ่านข้อมูลไม่ตรงกัน เพียงแต่ Phantom Read เป็นการอ่านที่เกี่ยวข้องกับข้อมูลมากกว่า 1 Document ขึ้นไป เช่น การ Read Documents ที่มี CreatedAt หลังจาก 01-01-2024 ขึ้นไป หรือแม้กระทั่งการ Count Documents ก็ตาม
ข้อดีข้อเสียของ Snapshot เหมือนกับการกำหนด Read Concern เป็น Majority เลยครับ เพียงแต่มีข้อดีเพิ่มเติมคือการอ่านข้อมูลเดียวกันมากกว่า 1 ครั้งใน Transaction เดียวกันจะได้ค่าที่เหมือนกัน
เผื่อใครอยากรู้เกี่ยวกับอีก 2 levels ที่เหลือครับ
Write Concern คืออะไร?
Write Concern คือ Configuration ที่ช่วยให้เราสามารถเลือกรูปแบบ Acknowledgement ของการ Write ได้ เพื่อความ Durability และ Consistency ของข้อมูลที่เขียน โดยสามารถเลือกได้ 2 รูปแบบดังนี้ครับ
1. {w: number}
จำนวนที่เป็นไปได้ก็ตั้งแต่ 0, 1, 2, 3 .. (ต้องไม่เกินจำนวน nodes ทั้งหมดใน Cluster) โดยจำนวนที่ระบุก็คือจำนวน Nodes ใน Cluster ที่ต้องการให้ Ack
ตัวอย่างที่ 1: {w: 0}
ไม่รอ Acknowledgement จาก Node ใดเลย ทำให้ Write Operation สามารถทำงานได้อย่างรวดเร็ว แต่ข้อมูลก็มีโอกาสที่จะถูกเขียนไม่สำเร็จ และถูก Rollback ได้
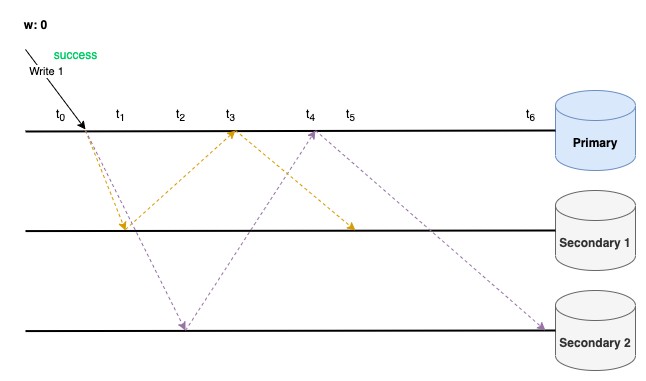
จากตัวอย่าง Client จะเห็นว่า Write 1 ทำงานสำเร็จทันทีโดยไม่ต้องรอการ Ack จาก Primary หรือ Secondary ใด ๆ
ข้อดี - Write Operation ทำงานได้อย่างรวดเร็ว
ข้อเสีย - ข้อมูลมีโอกาสที่จะเขียนไม่สำเร็จ และถูก Rollback ได้
ตัวอย่างที่ 2: {w: 1}
รอ Acknowledgement จากแค่ Primary Node เท่านั้น
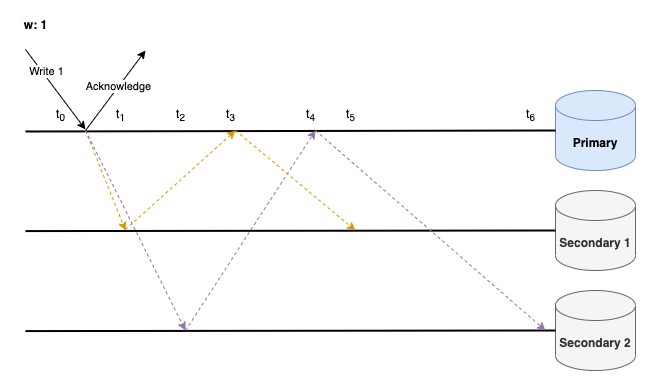
จากตัวอย่าง Write 1 จะสำเร็จได้ก็ต่อเมื่อมี Acknowledgement จาก Primary เท่านั้น
ข้อดี - Write Operation ทำงานได้อย่างรวดเร็ว (อาจไม่เท่า {w: 0}) และลดโอกาสที่ข้อมูลจะถูก Rollback ในภายหลัง (เทียบกับ {w: 0})
ข้อเสีย - ข้อมูลยังมีโอกาสที่จะเขียนไม่สำเร็จ และถูก Rollback ได้
ตัวอย่างที่ 3: {w: 3}
รอ acknowledgement จาก nodes ทั้งหมดใน cluster (ถ้าใน cluster ประกอบไปด้วย 3 nodes)
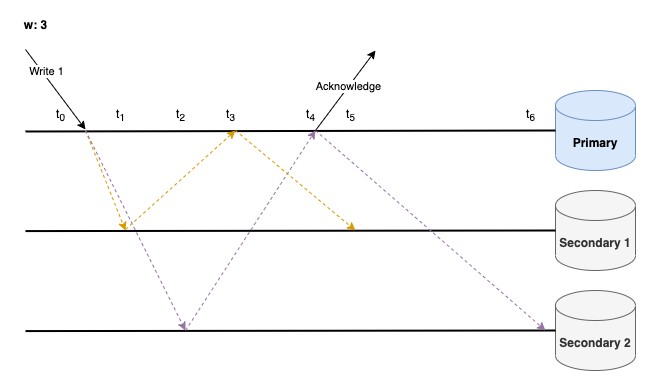
จากตัวอย่างมี Acknowledgement จาก 3 Nodes (Primary, Secondary 1, Secondary 2) แล้ว ณ เวลา t4 จึงถือว่า Write Operation นี้สำเร็จ
ข้อดี - มั่นใจได้ว่าข้อมูลไม่มีโอกาสถูก Rollback ในภายหลัง
ข้อเสีย - Write Operation กินเวลานานขึ้น, มีปัญหาเกี่ยวกับ Availability เนื่องจากอาจจะมี Node หนึ่งเกิด Crash ไปซะก่อน ก็จะทำให้ Write Operation ทำงานไม่สำเร็จซักที
อาจจะมีคำถามเกิดขึ้นว่า แล้วถ้าได้รับ Acknowledgement ไม่ครบตามจำนวนที่กำหนดล่ะ จะเป็นยังไง?
คำตอบคือ รอไปเรื่อย ๆ อย่างไม่มีกำหนดครับ
ปัญหาการรออย่างไม่มีกำหนดนี้ถูกแก้ได้โดย wtimeout ครับ
wtimeout (ms) คือ configuration นึงที่ใช้สำหรับการระบุ timeout ของ write operation โดยมีข้อแม้ว่าต้องระบุจำนวนของ Write Concern ให้มากกว่า 1 เช่น {w: 2} หรือ {w: 3}
สมมุติกำหนด {w: 3} และ wtimeout ไว้ที่ 10000 (10 วินาที) เมื่อ write operation ไม่ได้รับ acknowledgement จาก 3 nodes เกิน 10 วินาที MongoDB ก็จะ return error ออกมา อย่างไรก็ตามข้อมูลจาก write operation นี้ที่ถูกเขียนลงบน Primary แล้วก็จะไม่ถูก rollback
หมายเหตุ ค่า default ของ wtimeout คือ 0 หมายความว่าถ้าไม่มี acknowledgement จากจำนวน nodes ที่ต้องการ ก็จะต้องรออย่างไม่มีกำหนด
2. {w: ‘majority’}
การกำหนด Write Concern เป็น Majority คือ Write Operation จะต้องรอ Acknowledgement จาก Nodes ส่วนใหญ่ใน Cluster ก่อนจึงจะถือว่าการเขียนนั้นสำเร็จ
มาดูตัวอย่างกันดีกว่าครับ
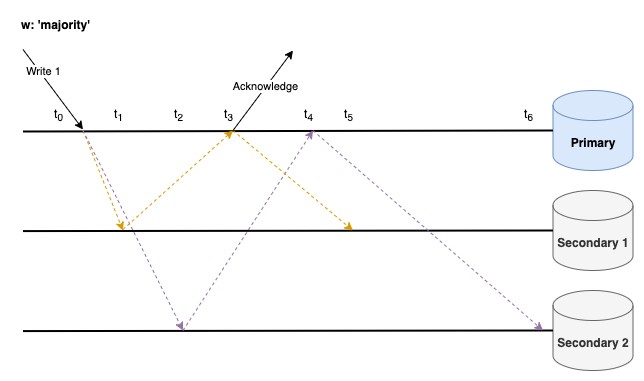
ลำดับเหตุการณ์
จากตัวอย่าง เมื่อมี Acknowledgement จาก Nodes ส่วนใหญ่ (Primary, Secondary 1) แล้ว ณ เวลา t3 ก็จะถือว่า Write Operation นั้นทำงานสำเร็จ
ข้อดี - มั่นใจได้ว่าข้อมูลไม่มีโอกาสถูก rollback ในภายหลัง
ข้อเสีย - Write operation ใช้เวลานาน
ค่า Default ของ Write Concern ขึ้นอยู่กับเงื่อนไขดังนี้
if ( (arbiters > 0) AND (nonArbiters <= majority(votingNodes)) ) {
defaultWriteConcern = { w: 1 }
} else {
defaultWriteConcern = { w: "majority" }
}

แถม Configuration ที่ใช้ร่วมกับ Write Concern ให้อีกตัว
{j: boolean}
เรียกง่าย ๆ ว่า Journal Acknowledgement คือการที่จะต้องมีการสร้าง Log ของ Write Operation ก่อนที่ Node นั้น ๆ จะทำการ Ack โดย Configuration นี้มีค่า Default เป็น False หมายความว่า Node จะ Ack โดยไม่คำนึงถึงว่า Log ของ Write Operation ถูกสร้างหรือยัง
ตัวอย่าง
กำหนดให้ {j: true}, {w: ‘majority’}, 1 Primary และ 2 Secondaries (Secondary 1 และ Secondary 2)
เมื่อข้อมูล Replicate มายัง Secondary 1 ข้อมูลจะถูกบันทึกและต้องมีการสร้าง Log สำหรับ Write Operation นี้ก่อนจะ Ack ให้แก่ Primary
ประโยชน์ของการสร้าง Log สำหรับ Write Operation ก่อนที่จะ Ack คือ เมื่อฐานข้อมูลเกิด Crash ขณะนั้นและถูก Recover ขึ้นมาใหม่ ข้อมูลก็จะไม่สูญหายเพราะ MongoDB มีการบันทึกข้อมูลต่าง ๆ เกี่ยวกับ Write Operation นั้นไว้ใน On-disk Journal แล้ว เมื่อ Recover ขึ้นมา MongoDB ก็จะหยิบ Write Operation นั้นมาทำงานใหม่
กำหนด Read Concern และ Write Concern ได้ที่ไหนบ้าง?
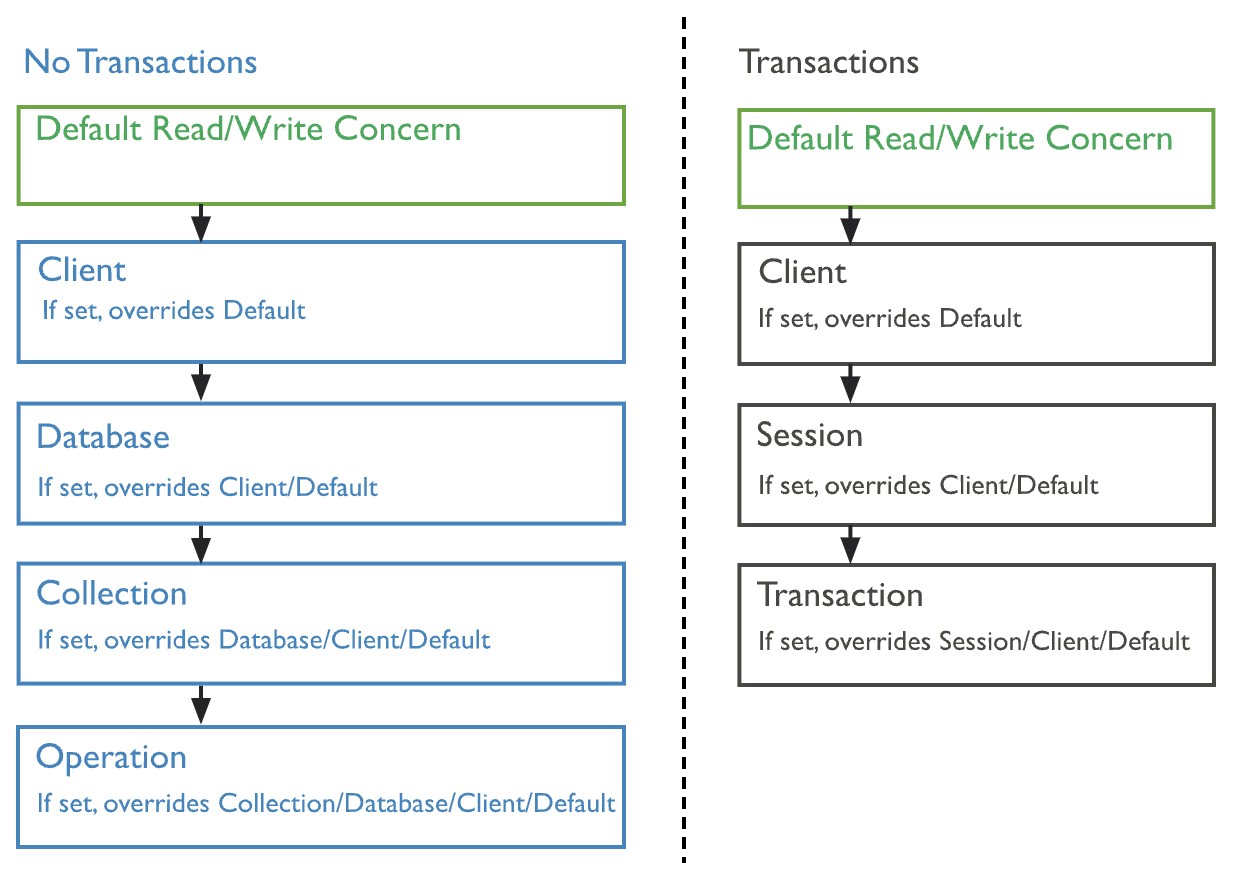
Cr: https://www.mongodb.com/docs/manual/reference/mongodb-defaults/
Final Word
ขอบคุณทุกคนที่อ่านกันจนจบครับ หวังว่าจะเป็นประโยชน์สำหรับผู้ใช้งาน MongoDB ทุกท่าน ถ้าผิดพลาดในจุดไหนต้องขออภัยมา ณ ที่นี้ด้วยครับ
tags : database mongodb thinknet software engineer thinknet software engineer