มาลองใช้ Elasticsearch Tokenizer ในสถานการณ์ต่างๆ

ลองใช้ Elastic Tokenizer ในสถานการณ์ต่างๆ

Picture by— @carolineattwood
ปัจจุบันการสร้างระบบ Search Engine แบบฉลาดๆนั้น ไม่ใช่เรื่องที่ไกลตัวอีกต่อไปแล้ว เพราะมีคนทำ tools ออกมาอย่างหลากหลายให้เราได้ใช้กัน
Elastic จะมีวิธีการเก็บข้อมูลเพื่อให้การค้นหารวดเร็ว และมีผลลัพธ์ออกมาตรงใจผู้ใช้ โดยจะต้องทำ Indexing (สารบัญ) ก่อนที่จะนำข้อมูลเข้าระบบ ทำให้ Tokenizer เข้ามาเป็นพระเอกของงาน
อ่านมาตั้งแต่แรก สำหรับคนที่เริ่มใช้จะรู้สึกว่า คำศัพท์แปลกๆเยอะมาก ซึ่งผมจะอธิบายอย่างง่ายที่สุดไปทีละตัว ก่อนเข้าเนื้อหานะครับ 555
Tokenizer คืออะไร
Algorithm ในการแบ่งแยกข้อความให้เป็นคำ/ตัวอักษร (แล้วแต่เรา) ตัวที่หั่นออกมา เราจะเรียกกันว่า “token”
พ่อเมืองภูเก็ต หารือหน่วยงานที่เกี่ยวข้อง เตรียมเคลื่อนย้าย “บ้านลอยน้ำ” กลับเข้าฝั่ง
จากข้อความดังกล่าว ผมจะลองแบ่ง (tokenize) ตามวิจารณญาณดูนะครับ
พ่อ|เมือง|ภูเก็ต|หารือ|หน่วยงาน|ที่|เกี่ยวข้อง|เตรียม|เคลื่อนย้าย |บ้านลอยน้ำ|กลับ|เข้า|ฝั่ง
คำที่แบ่งจะถูกคั่นไว้ ตามที่ผมคิดว่ามันควรจะเป็น ซึ่งจะมีผลกับกระบวนการ indexing ที่จะอธิบายต่อจากนี้
Indexing คืออะไร
จาก Tokenizer ที่ได้อธิบายไว้ข้างบน ก็จะนำมาสู่การนำไปทำสารบัญ ตอนนี้เรามีตัวอย่างที่เกี่ยวกับข่าวอยู่ 4 เรื่อง

เมื่อลองเอาทุกหัวข้อมาหั่น (Tokenize) แบบข้างบน จะได้ผลลัพธ์ประมาณนี้

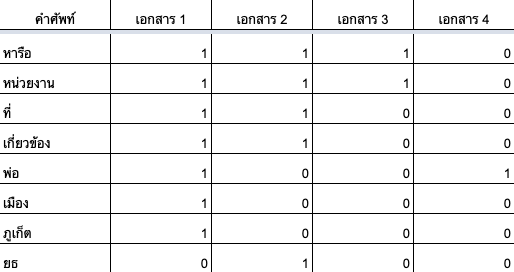
ตอนนี้ เราก็จะได้กลุ่มคำศัพท์มาชุดหนึ่ง ที่จะนำมาสร้าง index โดยจะดูว่าเอกสารแต่ละเอกสาร มีคำนี้คำนั้นกี่คำ หลังจากลองนับดูด้วยตา ก็จะได้ index ประมาณนี้
หลังจาก index ถูกสร้างมาแล้ว ต่อจากนี้การค้นหาก็จะถูกนำไป Tokenize เพื่อนำมาเทียบคะแนน (Scoring) ใน index ยกตัวอย่างเช่น คำค้นหา = หน่วยงานเมืองภูเก็ต
หน่วยงาน|เมือง|ภูเก็ต
ระบบจะนับคะแนน โดยอิงจากเอกสารที่มี 3 คำ ที่ได้แบ่งคำให้ดู
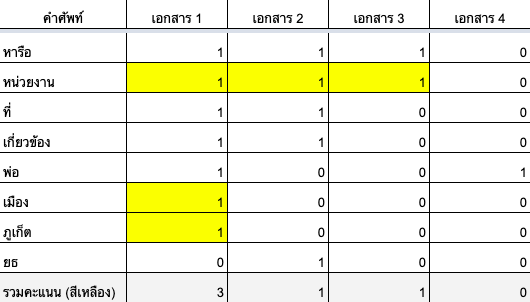
ดังนั้น จะได้ผลลัพธ์ของการค้นหาจำนวน 3 เอกสาร ก็คือเอกสารที่ 1, 2, 3 โดยได้คะแนน 3, 1, 1 ตามลำดับ
Tokenizer ที่กล่าวมาข้างต้นยังเป็นแค่หนึ่งในอีกหลายๆตัว ซึ่งมีการใช้งานในรูปแบบที่ต่างกันออกไป
Tokenizer
ถึงเวลามาเข้าเรื่องกันแล้ว โดยเรื่องที่กล่าวไปข้างต้นเป็นการยกตัวอย่างการค้นหาโดยใช้ Tokenizer ชนิดหนึ่ง ซึ่งในโลกความจริงแล้ว ผลลัพธ์ที่เราเอาออกมา อาจจะไม่ต้องถูกที่สุด แต่ควรจะตรงกับความต้องการของผู้ใช้ที่สุด ในบล็อกนี้ผมก็เลยจะขอหยิบ Tokenizer บางตัวมาลองให้ดูนะครับ
keyword
สำหรับการ match data ตรงตัวกับ input ที่เข้าไปเลย
ตัวอย่าง Keyword Tokenizer
POST _analyze
{
"tokenizer": "keyword",
"text": "การที่มีเธอมันก็ดี"
}
ผลลัพธ์ (แบบย่อ)
["การที่มีเธอมันก็ดี"]
thai, icu_tokenizer
thai tokenizer และ icu tokenizer มีลักษณะการตัดคำที่ค่อนข้างจะคล้ายกัน แต่จะมีผลลัพธ์ที่ไม่เหมือนกันหลายจุด โดยส่วนมากจะนำไปใช้กับการค้นหา document เชิงบทความ หรือเกี่ยวเนื้อความ ที่มีคำที่มีความหมายอยู่เยอะๆ
ตัวอย่าง Thai Tokenizer
POST _analyze
{
"tokenizer": "thai",
"text": "การที่มีเธอมันก็ดี"
}
ผลลัพธ์ Thai Tokenizer (แบบย่อ)
["การ","ที่","มี","เธอ","มัน","ก็ดี"]
ตัวอย่าง ICU Tokenizer
POST _analyze
{
"tokenizer": "thai",
"text": "การที่มีเธอมันก็ดี"
}
ผลลัพธ์(แบบย่อ)
["การ","ที่","มี","เธอ","มัน","ก็","ดี"]
ngram
เป็นตัวตัดคำที่อยู่ในลักษณะที่ดึงตัวอักษรมาทำ Index เป็นชุดๆ ตัวอย่างเช่น…
quick -> [q, qu, ui, ic, ck, k]
จะเห็นว่าการตัดข้อความ เราจะไม่สนใจความหมายของ document ดังนั้น ลักษณะในการนำไปใช้ที่มีประโยชน์ที่สุด จะเป็นเบอร์โทรศัพท์ กับ ชื่อเป็นส่วนใหญ่
ตัวอย่าง ICU Tokenizer
POST _analyze
{
"tokenizer": "ngram",
"text": "การที่มีเธอมันก็ดี"
}
ผลลัพธ์(แบบย่อ)
["ก","กา","าร","รท","ที","-ี่","-่ม","มี","-ีเ","เธ","ธอ","อม","มั", "-ัน","นก","ก็","-็ด","ดี","-ี"]
จากตัวอย่างข้างต้น ข้อความจะถูกหั่นเป็น 2 ตัวอักษร ซึ่งเอาจริงๆแล้วการค้นหาโดยใช้ ngram อาจจะได้ผลอยู่บ้าง แต่ว่าสิ่งที่เกิดคือ จะทำให้ได้ document (ขยะ) ที่ไม่เกี่ยวกับข้อความที่ user ต้องการ เนื่องจากการที่ match กับแต่ละตัวอักษรที่หั่นมาได้ในผลลัพธ์นั่นเอง
ดังนั้นถ้าหากลองเปลี่ยนมาใช้กับเบอร์โทรศัพท์ หรือชื่อบุคคล จะได้ผลลัพธ์ดังนี้
0912345678 => ["0","09","91","12","23","34","45","56","67","78","8"] สมชาย สายชม => ["ส","สม","มช","ชา","าย","ย "," ส","สา","าย","ยช","ชม","ม"]
ลองคิดถึงเวลาที่เราหาเบอร์โทรศัพท์หรือชื่อใครสักคนใน social network ดูครับ เราพิมไปแค่ไม่กี่ตัวหรืออาจจะมีพิมพ์ผิดบ้าง แต่โปรแกรมก็หาให้เราเจอ ซึ่งการใช้ ngram ก็จะช่วยเรื่องนี้ได้เหมือนกัน
นอกจากนี้ก็ยังมี tokenizer ตัวอื่นๆอีกหลายตัว ตามรูปแบบการใช้งาน ซึ่งอาจจะใช้ควบคู่กับ ตัว filter ที่มีหน้าที่ process ผลลัพธ์หลังจากที่ผ่าน tokenizer มาอีกต่อนึงได้
tags : elastic elasticsearch tokenizer searching search