Elasticsearch Lesson 4 : Search ranking and Scoring function

Search Ranking Definition
กำหนดให้ การค้นหา q และ เอกสาร Docs เป็นเอกสารที่ได้จากการค้นหา
แล้ว
Search ranking คือ sorting function ที่ใช้ในการเรียงลำดับเอกสาร Docs ภายใต้บรรทัดฐานหนึ่งๆ โดยให้ เอกสารที่เหมาะสมที่สุด ปรากฎก่อน ตามลำดับ ในผลลัพธ์จากการค้นหา q
แปลจาก [1]
การค้นหา (Query) หมายถึง ข้อมูลที่ผู้ใช้งานกรอกลงในแบบฟอร์มการค้นหาก่อนส่งให้ระบบเพื่อค้นหาข้อมูล
บรรทัดฐาน (Criteria) ในที่นี้ หมายถึง การตีความประโยชน์ที่เอกสารหนึ่งๆ มี โดยที่ประโยชน์มาก จะปรากฎก่อนในลำดับผลการค้นหา
บทความนี้จะกล่าวถึง การสร้าง Search ranking โดยใช้ Elasticsearch ภายใต้ระบบตัวอย่าง ที่เราออกแบบเตรียมไว้ให้

Practical Use
ซึ่งตัวอย่างระบบเป็น เวปไซต์ให้บริการข่าวสาร ต่างๆ โดยที่ให้บริการผู้ใช้งานเพื่อเข้ามา ค้นหาข่าว ดูข่าวใหม่ และข่าวที่เป็นกระแสสังคม
โดย feature การค้นหา อยู่ภายใต้บรรทัดฐานที่ว่า
"ข่าวที่ดีต้องมีผู้ชื่นชอบมาก"
เราจะสามารถเขียนสูตรการคำนวณคะแนนของข่าว (NewsScore) ภายใต้บรรทัดฐานได้ดังนี้
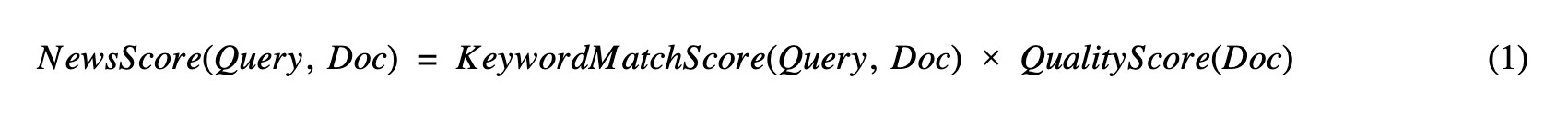
คะแนนของข่าวจะคำนวณจาก การเข้ากันของคำค้นกับเนื้อหาข่าว (KeywordScore) และ คุณภาพของข่าว (QualityScore) ดัง (1)
และหากโครงสร้างของข้อมูลข่าวประกอบไปด้วย พาดหัวข่าว (Title) และ เนื้อหา (Content) คะแนนการเข้ากันของคำค้นหาจะต้องคำนวณจากทั้งสององค์ประกอบด้วย ดัง (2)

และ ในส่วนของคุณภาพ ตามบรรทัดฐานที่กล่าวมานั้น คะแนนเชิงคุณภาพของข่าวจึงคำนวณได้จาก จำนวนครั้งของการชื่นชอบจากผู้ใช้งาน ดัง (3)
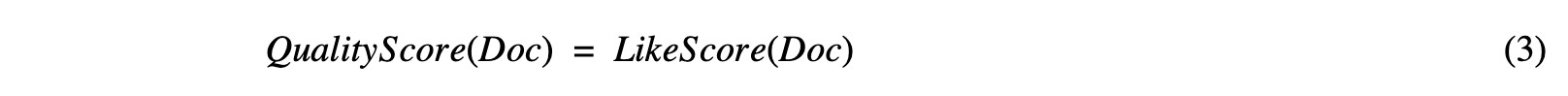
จากความต้องการของระบบดังที่กล่าวมานี้
บน elasticsearch เราสามารถพัฒนา search ranking ขึ้นมาได้ง่ายๆ จาก script_score ที่อยู่ใน function score query
script score query
การค้นหาด้วย script score [2] ช่วยให้เราปรับคะแนนเชิงคุณภาพของเอกสารจากการค้นหาได้

ซึ่งการใช้งาน จะต้อง "ระบุ" ขั้นตอนการคำนวณคะแนนจากองค์ประกอบต่างๆ ของเอกสารด้วย
จากโค้ด การค้นหานี้ คือ การค้นหาด้วยคำค้น elasticsearch และคูณคะแนนการเข้ากันของคำค้น กับ จำนวนการชื่นชอบที่ถูกหารด้วย 10 ในบรรทัดที่ 88
โดยที่ dsljson ทั้งหมดสามารถเอาได้จาก gist นี้
โดยเมื่อนำมาปรับใช้สำหรับพัฒนา feature ของเราจะได้ dsljson ดังนี้

จะได้ผลการค้นหาดังนี้
"_id": "3",
"news_title": "เลขที่รักจงมา พาสำรวจ 10 อันดับหวยขายดี คนดวงดีเหมายกแผงไปแล้ว",
"likes": 7,
"_score": 2.1972246,
"_id": "5",
"news_title": "'เดินหลงทางในวัด' ฝันสยอง มองเห็นเลขเด็ดโผล่ต้นตะเคียนวัดดังศรีสะเกษ",
"likes": 5,
"_score": 1.9459101,
"_id": "7",
"news_title": "16 แน่นอนกว่า 14 พาไปดูสถิติหวยออกวันที่ 16 ก.พ. เลขเด็ด ดัง เด่น มาเต็มๆ",
"likes": 4"_score": 1.7917595,
ซึ่งถ้าหากเราค้นหาโดยไม่ใช้ LikeScore เลยจะได้ลำดับผลลัพธ์ที่แตกต่างกันออกไปเป็น
"_id": "7",
"news_title": "16 แน่นอนกว่า 14 พาไปดูสถิติหวยออกวันที่ 16 ก.พ. เลขเด็ด ดัง เด่น มาเต็มๆ",
"likes": 4"_score": 3.3567505,
"_id": "5",
"news_title": "'เดินหลงทางในวัด' ฝันสยอง มองเห็นเลขเด็ดโผล่ต้นตะเคียนวัดดังศรีสะเกษ",
"likes": 5,
"_score": 1.4564657,
"_id": "3",
"news_title": "เลขที่รักจงมา พาสำรวจ 10 อันดับหวยขายดี คนดวงดีเหมายกแผงไปแล้ว",
"likes": 7,
"_score": 0.48484862,
การใช้ script_score ช่วยให้คำนวณค่า QualityScore ที่ได้จากองค์ประกอบอื่นๆ ของเอกสารได้
แต่... ข่าวที่ดี มันต้องใหม่ด้วยป่ะ?
ซึ่งถ้าหากเราต้องการปรับบรรทัดฐานให้ละเอียดอ่อนยิ่งขึ้น เป็น
"ข่าวที่ดีต้องเป็นข่าวใหม่และมีผู้ชื่นชอบมาก"
QualityScore จะถูกคำนวณด้วยปัจจัยที่เพิ่มขึ้น ดัง (4)
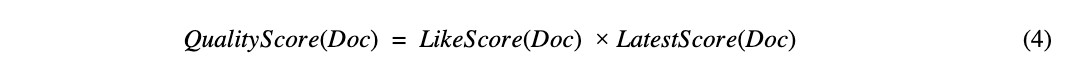
ซึ่งบน elasticsearch การคำนวณคะแนนจากข้อมูลวันเดือนปี นั้นสามารถคำนวณได้จาก
Decay Function
Decay function [3] ช่วยให้เราคำนวณค่าจากฟังก์ช้นการกระจ่ายซึ่งมีให้เลือก 3 แบบด้วยกันคือ แบบเชิงเส้น (linear) แบบเอ็กโพเนนเชียล (exp) และแบบเกาส์ (gauss) โดยตัวอย่างการค้นหาเป็นดังนี้

ซึ่งเมื่อนำไปผสมผสานกับการค้นหาก่อนหน้านี้ จะได้

จากการค้นหา เราได้ปรับเปลี่ยนการคำนวณคะแนนความชื่นชอบ โดยใช้ field_value_factor [4] เพื่อให้การคำนวณคะแนนรวดเร็วขึ้น
โดยผลลัพธ์ที่ได้จากการค้นหา ก็จะมีลำดับผลลัพธ์ที่แตกต่างกันออกไปดังนี้
"_id": "5",
"news_title": "'เดินหลงทางในวัด' ฝันสยอง มองเห็นเลขเด็ดโผล่ต้นตะเคียนวัดดังศรีสะเกษ",
"likes": 5,
"publishDate": "2019-02-28"
"_score": 2.0221848,
"_id": "7",
"news_title": "16 แน่นอนกว่า 14 พาไปดูสถิติหวยออกวันที่ 16 ก.พ. เลขเด็ด ดัง เด่น มาเต็มๆ",
"likes": 4"publishDate": "2019-02-01"
"_score": 1.5064259,
"_id": "3",
"news_title": "เลขที่รักจงมา พาสำรวจ 10 อันดับหวยขายดี คนดวงดีเหมายกแผงไปแล้ว",
"likes": 7,
"publishDate": "2019-02-10"
"_score": 0.42357036,
ไหนเรามาลองวิเคราะห์กันหน่อยว่า มันเกิดอะไรขึ้นบ้างน่ะ สำหรับแต่ละการค้นหาที่กล่าวมา
วิเคราะห์ผลการค้นหา
หากเรานำข่าวทั้ง 3 ข่าวดังที่ปรากฎในผลลัพธ์การค้นหาข้างต้น มาพิจารณาโดยใช้ explain:true เพื่อดูค่าคะแนนที่ได้จริง และนำไปเปรียบเทียบคะแนนที่ได้แต่ละส่วนของทั้งสามเอกสาร จะได้ดังรูป
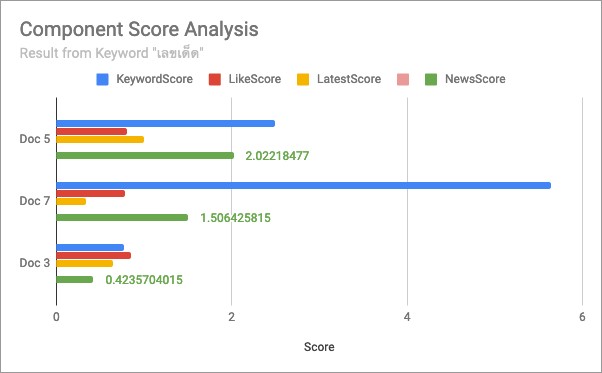
จาก (1) และ (4) คะแนน NewsScore (สีเขียว) ได้จากการคูณกันของ KeywordScore (ฟ้า) LikeScore (แดง) และ LatestScore (เหลือง)
เอกสารที่ 7 ถูกปรากฎก่อนเอกสารที่ 3 เพราะว่า
เนื้อหาปรากฎคำที่ถูกค้นหามากกว่า
ถึงแม้ข่าวจะไม่อัพเดทเท่าไหร่
เราก็หวังว่า ทุกคนจะสามารถ
ทำให้ content ดีๆ ถูกปรากฎบ่อยขึ้นในผลลัพธ์การค้นหาได้แล้วน่ะ
โดยในบทความถัดไป จะเกี่ยวกับการวัดประสิทธิภาพของ ฟังก์ชันการให้คะแนนที่เราทำให้ดูในบทความนี้นี่แหล่ะ
ว่าผู้ใช้งานนั้น โอเคกับผลลัพธ์การค้นหามากน้อย เพียงใด
ฝากติดตาม รับชมรับฟังกันน่ะคร้าบบบบ
ซอสโค้ดทั้งหมดในบทความนี้ สามารถเอาได้จาก ที่นี้ ครับ
อ้างอิง
[1] https://en.wikipedia.org/wiki/Ranking_(information_retrieval)
บทเรียนก่อนๆ
- lesson 1 : https://blog.thinknet.co.th/tech/elasticsearch-lesson-1%C2%A0-simple-thai-search-engine
- lesson 2 : https://blog.thinknet.co.th/tech/elasticsearch-lesson-2-approaches-for-named-entity-field-search
- lesson 3 : https://blog.thinknet.co.th/tech/elasticsearch-lesson-3-how-to-personalize-search-result
tags : elasticsearch search ranking scoring function news news search script score decay function search engine field value factor