การค้นหาผ่าน Google Maps
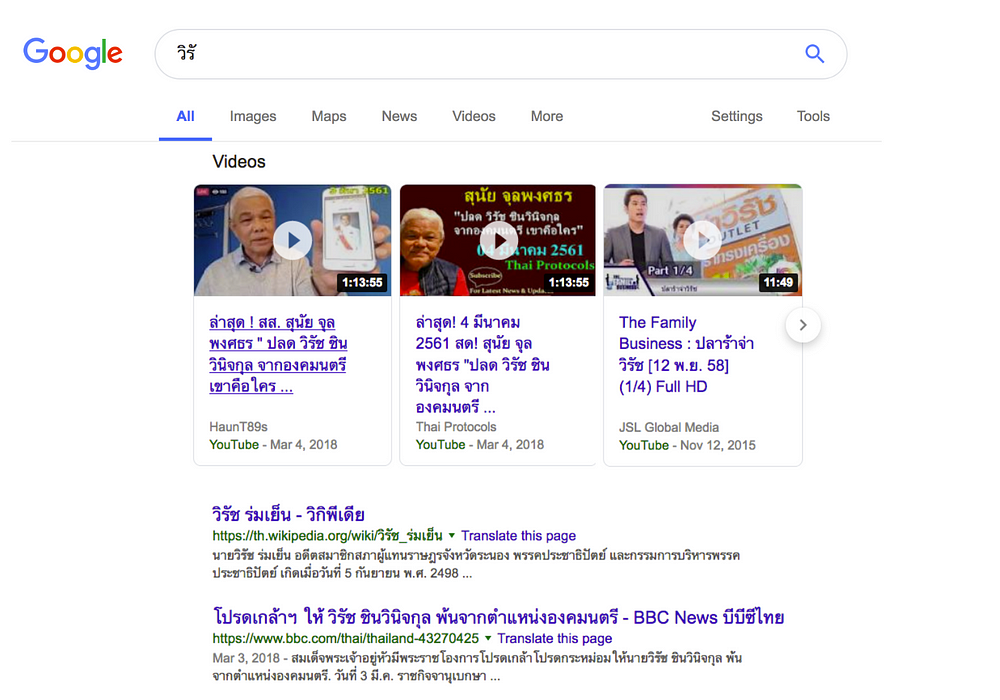
หลายคนคงเคยเจอประสบการณ์ที่ต้องค้นหา อาทิเช่น ชื่อบุคคล
นาย วิรัช อยู่ยั่งยืน
หรือ ชื่อสินค้า
DVD RW SATA 24X ASUS รุ่น 24D5MT (Box)
ซึ่งไม่ว่าจะใส่คำค้นหาอะไรก็ตาม ก็ไม่ยักเจอผลลัพธ์ที่ต้องการเสมอ หรือถ้าจะเจอก็ยากอ่ะ
ก็จะมี เครื่องมืออีกมากมาย ไม่ว่าจะเป็น JQuery.autocomplete หรือ เครื่องมืออื่นๆ ที่สามารถนำผลการค้นหามาแสดงผลให้ผู้ใช้สะดวกขึ้น เพื่อให้ การค้นหาสิ่งต่างๆ จากชื่อเฉพาะของมันให้ง่ายขึ้นนิดนึง
จาก Lesson 1 เรามีท่าในการวิเคราะห์ข้อความโดยใช้ icu_tokenizer กับ shingles

ซึ่งถ้าเราใช้กับชื่อเฉพาะ ผลลัพธ์เป็นไงเราไปดูกันครับ
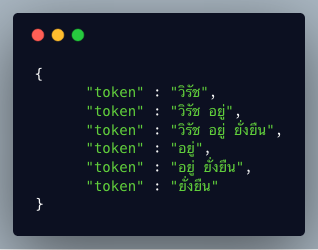
ผลลัพธ์ออกมามันก็ดูโอเค น่าจะใช้งานได้ ดูเป็นคำๆ
ทีนี้เราก็มาลองค้นหาดูบ้าง ซึ่งปกติแล้วการค้นหาชื่อที่ดี ไม่ต้องพิมพ์ ถูกต้อง ครบถ้วน มันก็ควรจะค้นเจอได้บ้าง

ถ้าเราค้นหาโดยใช้ ชื่อเต็มๆ ที่เขียนถูกต้อง ไม่ผิดเลย มันก็ค้นหาเจอน่ะครับ
แต่ถ้าจะพิมพ์แค่บางส่วนของชื่อ มันดันค้นไม่เจอแฮะ
ที่กล่าวมาก็จะพูดสั้นๆ ได้ว่า
ค้นชื่อเฉพาะยาก ต้องพิมพ์ครบ ถูกต้องทั้งคำ ถึงจะเจอ
ก็มันชื่อเฉพาะนี้ ทำไงได้
ทีนี้ก็ลองมาดูท่าใหม่ในการวิเคราะห์ชื่อเฉพาะดูครับ
NGram Tokenizer for Compound Words
N-gram tokenizer [1] คือการนำเอาสายอักขระ มาสร้างเป็นสายอักขระย่อย โดยใช้อักขระที่ติดกันจำนวน N อักขระจากสายอักขระหลัก เช่น คำว่า “ปรารถนา”
ความยาว 1 อักขระ จะได้ [ป,ร,า,ร,ถ,น,า]
ความยาว 2 อักขระ จะได้ [ปร, รา, าร, รถ, ถน, นา]
ความยาว 3 อักขระ จะได้ [ปรา, ราร, ารถ, รถน, ถนา]
ความยาว 4 อักขระ จะได้ [ปราร, รารถ,ารถน, รถนา]
ความยาว 5 อักขระ จะได้ [ปรารถ, รารถน, ารถนา]
งี้มันก็สร้าง inverted index ออกมาเยอะมากเลยอ่ะดิ
“ใช่แล้ว”
แนวทางในการลดปริมาณ inverted index term ลงหากจำเป็นต้องใช้ Ngram tokenizer จริงๆ คือการเพิ่มขนาด min_gram ให้สูง และ ลดขนาดของ max_gram ให้มีค่าใกล้กับ min_gram มากที่สุด จะสามารถลดปริมาณ term ลงได้ ซึ่งกระทบกับ precision / recall ทำให้ผลการค้นหาเปลี่ยนแปลงไปได้
ทีนี้ก็ไปดูบ้างว่าเวลาใช้ทำไง
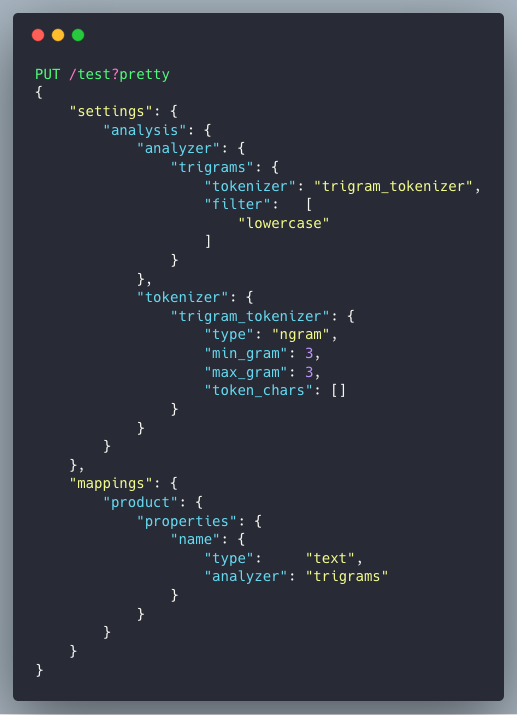
Put Mapping & Post Data
สร้าง Custom Analyzer ชื่อ trigrams โดยเรียกใช้ ngram tokenizer ที่กำหนดค่า min_gram และ max_gram กับ lowercase filter
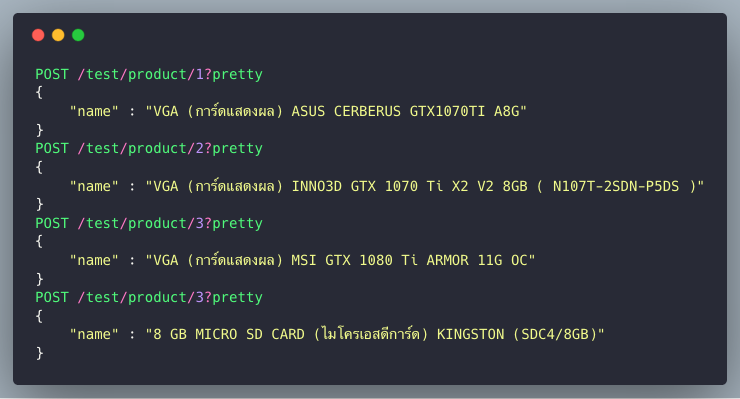
ก็ใส่ข้อมูลสินค้าเข้าไปเพื่อทดลองค้นหาดู ขอบคุณตัวอย่างข้อมูลจาก JIB
แล้วก็ลองค้นหาดูซิ โดยเริ่มจาก keyword “GTX” ดูก่อน
 ผลการค้นหาด้วย "GTX"
ผลการค้นหาด้วย "GTX" มันก็ค้นหาได้ถูกต้องน่ะ
แล้วก็ลองใช้ อักขระแปลกๆ เข้าไปแทรกดูหน่อย “GTX:1070”
 ผลการค้นหาด้วย "GTX:1070"
ผลการค้นหาด้วย "GTX:1070" ก็ค้นเจอทั้งสองชิ้น แฮะ
เพราะว่า “GTX:1070” นั้นถูก analyze
ให้อยู่ในรูป trigram ที่ประกอบด้วย
"GTX", "TX:", "X:1", ":10", "107", "070" โดยที่
มี 3 ตัวดังนี้ “GTX”, “107”, “070” ซึ่ง
พบเจอทั้ง 2 ชิ้น
หากลองใช้คำค้นที่มีการพิมพ์ผิดจาก “cerberus” เป็น “ceberus” (ตัด R ตัวแรกออก) ซึ่งจะทำให้ term [cer, erb, rbe] ที่จะหายไป แต่ก็ยังมี term อื่นๆ ที่ได้จาก trigram ที่ ถูกพบในชื่อของสินค้านี้อยู่
ผลการค้นหาด้วย "ceberus"
พิมพ์ keyword ผิด ก็ค้นเจอชื่อที่เขียนถูกได้
แต่อย่าเพิ่งนิ่งนอนใจไปครับ ลักษณะการสร้าง inverted index โดยใช้ N-gram นั้น หากเทียบกับ Word segmentation ตรงๆ แล้ว จะเกิด inverted index term ขึ้นมามากกว่า เมื่อสร้าง index จากชุดเอกสารเดียวกัน จึงมีแนวโน้มทำให้ การค้นหาภายใต้การใช้งาน N-gram นั้นมักเกิด recall ที่แย่กว่า หรือเรียกว่า
ผลการค้นหาจะกว้างและไม่ตอบโจทย์ได้
และจะเห็นผลลัพธ์ได้ชัดเมื่อมีจำนวนเอกสารยิ่งมากขึ้น ซึ่งหากตามไม่ทัน เรามีตัวอย่างให้ดู เช่น
ค้นหาคำว่า “ไมโครเอสดีการ์ด”
 ผลการค้นหาด้วย "ไมโครเอสดีการ์ด"
ผลการค้นหาด้วย "ไมโครเอสดีการ์ด" จะเห็นได้ว่า นอกจาก สินค้า “MICRO SD CARD” แล้ว ผลการค้นหายังมี VGA อีก 2
ชิ้นด้วยกัน
เพราะ มีส่วนที่เหมือนคือคำว่า “การ์ด” ซึ่งไกลจากคำค้นหา
“ไมโครเอสดีการ์ด” อยู่มาก
ผลการค้นหาที่กว้าง ลักษณะนี้ คือตัวอย่างของผลลัพธ์ที่ไม่ตอบโจทย์ ที่กล่าวมาได้
แนวทางการแก้ไขปัญหา recall ที่แย่ คือ การกำหนด term ขั้นต่ำที่ต้องพบใน ชื่อสินค้า โดยใช้ minimum_should_match [2]
พอใช้ minimum_should_match : 50 แล้วสามารถกรองผลลัพธ์ที่พบน้อยกว่าครึ่งนึงออกไปได้
จากตัวอย่าง code ทั้งหมดที่ใช้ดูได้จาก gist นี้ครับ