เมื่อไหร่ถึงค่อยใช้ การค้นหาผ่าน inverted index
- จำนวนเอกสารภายในระบบเพิ่มขึ้นทุกๆ ปี
- การค้นหาแบบ string matching[1] ที่เป็นอยู่ใช้เวลานานเกินรอ
- ผลการค้นหา มีเยอะเกินกว่าจะอ่านไหวและเริ่มไม่ตอบโจทย์ความต้องการ
Document content
ข้อมูลเนื้อหาภายในเอกสารที่ใช้ในการสร้าง inverted index ส่วนมากจะเขียนโดยใช้บรรยายโวหาร อธิบายถึงคุณลักษณะต่างๆ ที่ตัว เอกสารหนึ่งๆ แทนอยู่ ไม่ว่าจะเป็น สิ่งของ เช่น
รองเท้า : ใส่นุ่มสบาย ใช้ได้ทนทาน
หนังสือการ์ตูน : ฆาตกรรมในห้องปิดตาย โดยมีนักสืบตัวจิ๋ว คอยไขปริศนา
หรือเป็นเรื่องราว
ชาวนาคนหนึ่งคิดหาวิธีไล่นกที่มากินข้าวในนาของตน ด้วยความที่เขาเป็นคนขี้สงสารเลยไม่อยากวางยาหรือยิงพวกมัน ทุกครั้งที่พวกนกบินมาเขาได้แต่กางแขนวิ่งไปโบกไล่นก เมื่อฝูงนกเห็นชาวนาวิ่งมาก็พากันบินหนี แต่พอชาวนาหันหลังกลับพวกมันก็บินมาลงนาตามเดิม
เป็นต้น
Indexing Process
ขั้นตอนการทำดัชนีฐานข้อมูลเริ่มจากนำข้อมูลเนื้อหาของเอกสารมาผ่านขั้นตอนการตัดคำ และนำ term ที่ได้มาสร้าง inverted index และเมื่อต้องการค้นหา keyword ที่ใช้ก็จะถูกตัดคำและคำนวณเทียบกับ inverted index ที่สร้างขึ้น และเรียงลำดับผลลัพธ์ตามคะแนน
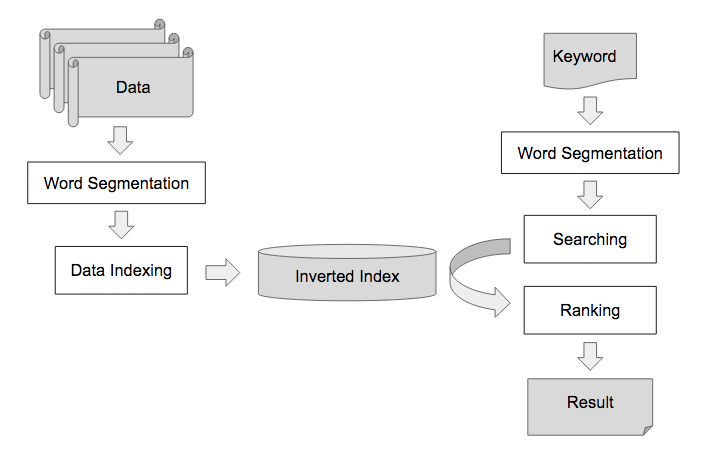
เผื่อไม่เห็นภาพ เราก็จะมีตัวอย่างเอกสาร และ inverted index หลังจากที่ผ่านการตัดคำแล้วให้ดูดังรูป
You know, for search
Elasticsearch[2] เป็น software ระบบการค้นหา ที่เบื้องหลังคือ Apache Lucene โดยที่ ภายใน Elasticsearch จะมี Module ที่ทำขั้นตอน Word Segmentation เรียกว่า Analyzer โดยจะมีอยู่ด้วยกัน 2 ตัวด้วยกันที่สามารถตัดคำภาษาไทยได้
ตัวอย่างการเรียกใช้ icu_tokenizer
- thai analyzer
- icu_tokenizer[3] (ติดตั้ง)
การคุยกับ elasticsearch คุยผ่าน http request ภายใต้ dsl-json format ของทาง elasticsearch
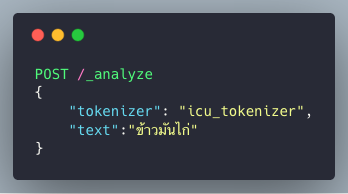
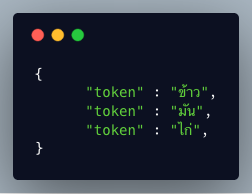
โดยจะได้ผลลัพธ์การตัดคำออกมาดังรูป
หมายเหตุ : analyzer : thai มีอยู่แล้วใน default build แต่ icu_tokenizer ต้องติดตั้ง เพิ่มเติมก่อนจึงสามารถใช้งานได้
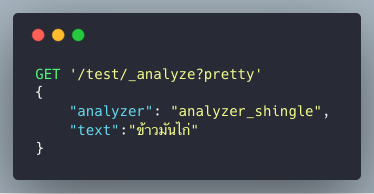
analyzer_shingle เป็น custom analyzer (ดู PUT MAPPING เพิ่มเติม)
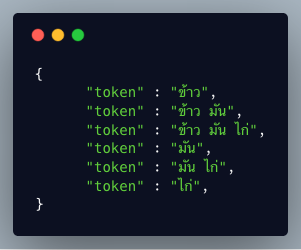
curl แล้ว grep “token”
Filter เป็นเครื่องมือตัวช่วยในการจัดการกับ term ที่ได้จาก tokenizer ก่อนที่จะนำไปสร้างเป็น inverted index โดยจุดประสงค์ ให้การเรียงลำดับผลลัพธ์ที่ดีที่สุด
ในที่นี้ทำหน้าที่ของ Shingle Token Filter[4] คือ สร้าง inverted index จากการต่อกันของ token ที่ติดกันจากสาย token เดิม ดังตัวอย่าง คำว่า “ข้าวมันไก่”
เมื่อใช้ Shingle Token Filter แล้ว เราก็จะได้ term ที่เป็นคำเต็มๆ ออกมา
นั่นก็คือคำว่า “ข้าวมันไก่” นั่นเอง
คำเตือน : การแก้ปัญหาโดยการรวบ term ที่ติดกันนั้น มาสร้าง term ใหม่ เป็นการ trade-off ระหว่าง precision/recall[6] และ index size ของระบบการค้นหา
TL;DR
Put Mapping & Post Data
เมื่อถึงคราวจะใช้งานจริง เราก็สร้าง Custom analyzer ที่เรียกใช้ icu_tokenizer และ shingle filter และก็ใส่ข้อมูลเข้าไปลอง query ดู
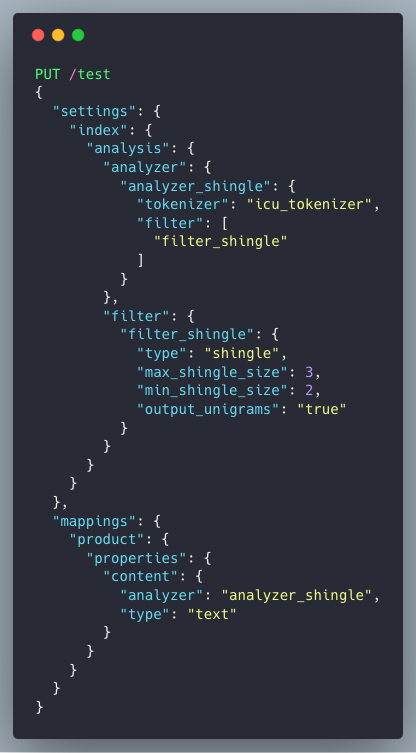
ขั้นตอนการ put mapping ใน elasticsearch เทียบเท่ากับขั้นตอนการสร้าง schema ของ SQL database ต้องมีการระบุ
- ชื่อของ field ในที่นี้ชื่อ content โดยเป็นประเภท text
- ใช้งาน ใน index ชื่อ test
- ใช้ analyzer ชื่อ analyzer_shingle
โดยมีการสร้าง Custom Analyzer ชื่อ analyzer_shingle ซึ่งประกอบด้วย
- tokenizer : icu_tokenizer
- filter : shingle
type ชื่อ product ตามด้วย id 1, 2, 3
ที่นี้ ก็ลองเอาข้อมูลใส่เข้าไปดูซิ
Query Document
ภายใน index จะมี inverted index ที่ถูกสร้างจากการ put mapping และ post data เข้าไป เมื่อมีการ query ข้อความจะถูกแบ่งเป็น term ต่างๆ และถูกนำไปเทียบกับ index ที่สร้างขึ้น โดยคำนวณคะแนนด้วย TF-IDF[5]
ref img จาก https://chrisalbon.com/machine_learning/preprocessing_text/tf-idf/
คะแนนของแต่ละ term ในการเทียบกับเอกสารหนึ่ง คิดจาก
จำนวนครั้งในการปรากฎ term นั้นในเอกสาร (ยิ่งมากยิ่งดี)
และ
ค่าผกผันของ จำนวนเอกสารที่ปรากฎ term นั้น (ยิ่งน้อยยิ่งดี)
โดยการคิดคะแนนรวมกันของแต่ละ term มีแบบ การบวก กับ การคูณ กัน
กลับสู่การ query ของเราต่อ
ลอง query โดยใส่คำว่า “มันไก่” จะได้ผลลัพธ์จากการ ranking ได้เอกสารลำดับที่ 1 “ฉันจะไปกินข้าวมันไก่” ก่อน เอกสารที่ 2 “ไก่ย่างถูกเผา มันจะถูกไม้เสียบ” เพราะว่า เอกสารที่ 1 มี term “มัน ไก่” ที่ได้จาก shingle filter ทำให้ได้คะแนน ranking ที่สูงกว่า

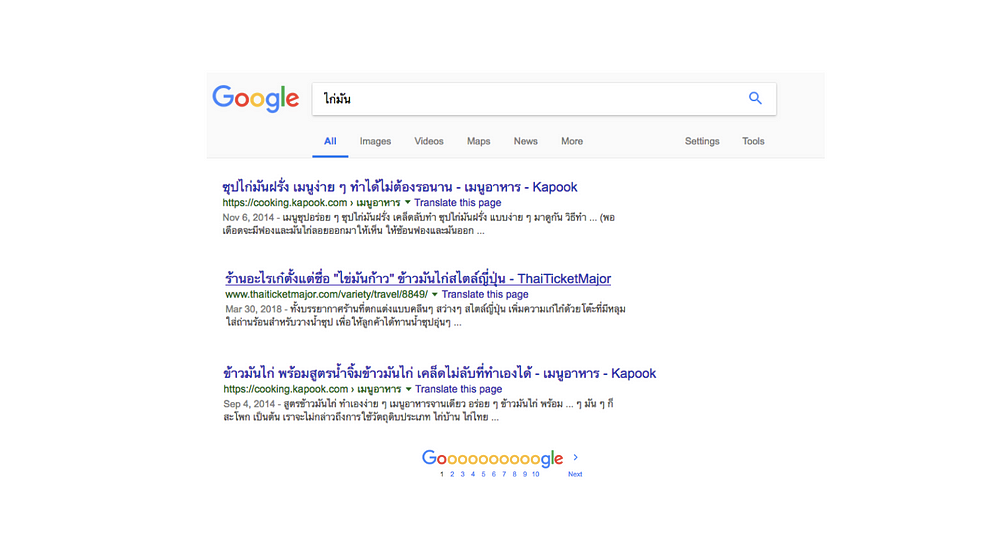
แต่หากลอง query โดยใช้คำว่า “ไก่มัน” ดูบ้าง ซึ่ง term “ไก่มัน” ไม่เคยปรากฎในเอกสารใดๆ มาก่อนเลย ทำให้คะแนนที่ได้จาก ranking ออกมาใกล้เคียงกันมาก ซึ่งเมื่อเป็นสถานการณ์จริง เอกสารอันใดอันหนึ่งอาจ ขึ้นก่อนอีกอันนึงก็ได้

พอเรา query ด้วยคำเต็มๆ “ข้าวมันไก่” ซึ่งจะมีอยู่หลาย term ที่ปรากฎ อยู่ในเอกสารที่ 1 เช่น “ข้าว มัน”, “มัน ไก่” และ “ข้าว มัน ไก่” เอง ทำให้คะแนนที่ได้นั่นสูงกว่า เอกสารที่ 2 มาก