ความสัมพันธ์ของ precision และ recall ใน ngram tokenizer

เริ่มทำความรู้จัก ngram tokenizer กันก่อน
ใน elastic มี tokenizer อยู่หลายๆตัว ngram คือหนึ่งในนั้น
ความสามารถของมันเอาไว้ตัดคำ ให้เป็น token (นำไปใช้ในการคำนวนคะแนนในการค้นหา) โดยหน้าตาของการ tokenize จะเป็นประมาณนี้

ตัวอย่างนี้ ผมลองใช้ ngram กับคำว่า "123"
ขอยกตัวอย่างกับตัวเลขเพื่อให้เห็นภาพได้ง่ายขึ้น
ผลลัพธ์ที่ได้คือ
"1","12","2","23","3"
เอ๊ะ ทำอะไรเอ่ย
ngram จะตัดคำตามจำนวนที่ตั้งไว้ให้เป็น token (default>>min:1, max:2)
ตัดเริ่มต้นที่ "1" >> 1 ตัวอักษร , "12" >> 2 ตัวอักษร , เลื่อนต่อไปที่ "2">> 1 ตัวอักษร , "23" >> 2 ตัวอักษร , เลื่อนต่อไปที่ "3">> 1 ตัวอักษร และเป็นตัวสุดท้ายเพราะไม่มีตัวอักษรต่อแล้ว
ลองปรับค่า ngram (min:2, max:3)
ผลลัพธ์ที่ได้คือ
"12","123","23"
น่าจะพอเข้าใจกันแล้ว ขอข้ามขั้นตอนไป ถึงประสบการณ์ได้ลองเล่นเลยแล้วกันนะครับ
ประสบการณ์นี้ได้จาก workshop ที่ทางบริษัทได้จัดขึ้น
workshop นี้เนื้อหาเกี่ยวกับการปูพื้นฐานเกี่ยวกับการค้นหาและได้ kibana
ในหัวข้อ exercise ได้ให้ลองค้นหาและสร้าง mapping เอง เกี่ยวกับ
เบอร์,ข่าว,ชื่อ-นามสกุล และอื่นๆ ซึ่งผมก็จะไม่ได้พูดลึกไปถึงตรงนั้น
เริ่มที่ผมใช้ ngram กับข้อมูลการ์ดจอ

ผมตั้งค่า ngram เปลี่ยนค่า min = 1 และ max = 3 ในที่นี้ควร
**ข้อควรระวัง การตั้งค่า min และ max ควรห่างกันแค่ 1 เนื่องจากหากข้อมูลมีเยอะมากๆ จะทำให้การ tokenize ใช้ ram เยอะ
หน้าตาข้อมูลตัวอย่าง 10 ข้อมูล (สมมุติให้ข้อมูลตัวอย่างเปรียบเป็นเบอร์โทรศัพท์)
{ "phone_number": "242245550"}
{ "phone_number": "241442560"}
{ "phone_number": "266422550"}
{ "phone_number": "3113113880"}
{ "phone_number": "2442445850"}
{ "phone_number": "0313113830"}
{ "phone_number": "246842550"}
{ "phone_number": "8285432890"}
{ "phone_number": "4383115810"}
{ "phone_number": "7365112870"}มาลองค้นหาเบอร์กันเลย


หน้าตาผลลัพธ์ที่ได้ก็ประมาณนี้
ช่วงวิเคราะห์ผลลัพธ์ 1: ผมค้นหาด้วย "0313113830" ก็จะเจอเบอร์ทั้งหมด 10 เบอร์แต่ score ก็จะแตกต่างกันไป
***ขอปรับ query หน่อย หากผมอยากได้เบอร์ที่ต้องการแค่เบอร์เดียว


หน้าตาผลลัพธ์ที่ได้ก็ประมาณนี้
ช่วงวิเคราะห์ผลลัพธ์ 2 : สิ่งที่ผมทำคือเพิ่ม operator : and ซึ่งตัวนี้จะช่วยเพิ่มความแม่นยำในการค้นหา หรือ (precision) และลดจำนวนข้อมูลที่เป็นไปได้ (recall) ลง ผลที่ได้คือจะเจอเบอร์ "0313113830" เพียงเบอร์เดียว
เจอคำศัพท์ใหม่ precision กับ recall คืออะไรเอ่ย
precision
คือความแม่นยำในการค้นหา ในที่นี้ ผมค้นหา "0313113830" ทั้งของ query ได้ผลลัพธ์ที่ต่างกัน โดยผลลัพธ์ที่ 2 จะเจอเบอร์เพียงเบอร์เดียว
recall
คือการเพิ่มจำนวนผลลัพธ์ในการ search นั้นจะตรงกันข้ามกับ precision หากค่าของ recall มาก จำนวนผลลัพธ์ก็จะเจอมากขึ้น จะเห็นได้จากตัวอย่างว่าจริงแล้วๆ แล้วในข้อมูลมีเบอร์ ที่มี "0","3","1","3","1","1","3","8","3","0" เป็นส่วนประกอบในผลลัพธ์ที่หนึ่ง หากไม่ใส่ operation and ทำให้การค้นหาของเราเจอผลลัพธ์นั้นเอง (การค้นหามีความคลาดเคลื่อน)
- เปรียบเทียบ precision : ผลลัพธ์ 1 < ผลลัพธ์ 2
- เปรียบเทียบ recall : ผลลัพธ์ 1 > ผลลัพธ์ 2
ยกตัวอย่างให้เห็นภาพเกี่ยวกับ recall มากขึ้น
***ขอปรับ query หน่อย หากผมจำเบอร์ของลูกค้าผิด หรือพิมผิดเป็น

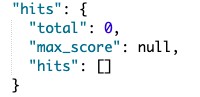


หากเราเน้น precision มากเกินไปในผลลัพธ์ที่ 3 หากเราพิมผิดไปแค่ 1 ตัวอักษรก็จะทำให้ไม่เจอผลลัพธ์เลย และสังเกตได้ว่า ผลลัพธ์ที่ 4 ปรับให้สนใจ recall ด้วยก็จะได้ผลลัพธ์เบอร์ "0313113830" แต่ score ก็จะน้อยกว่าผลลัพธ์ที่ 1 (เข้าใจว่า score แผลผันตรงกับ precision)
**ส่วน ngram token filter ก็ทำหน้าที่เหมือนกับ ngram tokenizer เลยแต่จะมีปัญหากับภาษาไทยอยู่นะ
สรุป
ใน workshop ที่ผมได้ลองเล่น elastic กับข้อมูลรูปแบบต่างๆอย่างที่ได้บอกไปได้รับรู้ว่า ngram นั้นเหมาะกับข้อมูลที่เรารู้ความยาวของข้อมูลอย่างชัดเจน หรือไม่ยาวเกินไปเช่น เบอร์โทรศัพท์ ชื่อคน รวมไปถึงจำนวนข้อมูลที่ไม่เยอะ แต่หากข้อมูลเยอะ และเนื้อข้อมูลยาวมากๆ ความแม่นยำก็จะต่ำลง
tags : elastic ngram tokenizer elasticsearch